
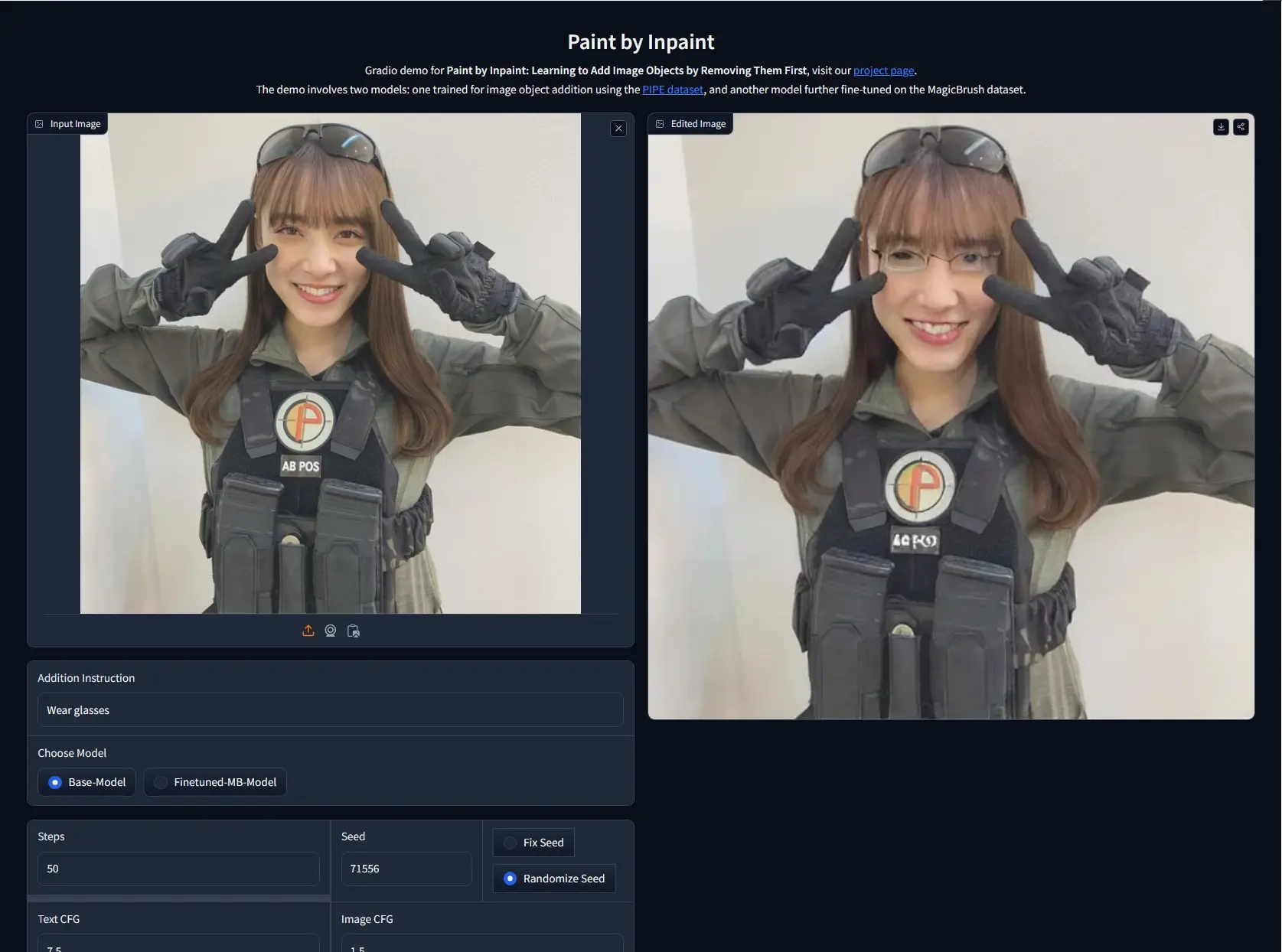
来自魏茨曼科学研究所和以色列理工学院的研究人员推出一种新颖的图像编辑技术Paint by Inpaint,它能够根据文本指令在图像中添加对象,而无需用户提供输入遮罩(mask)。这项技术的核心在于利用了一个观察结果:从图像中移除对象(Inpaint)比添加对象(Paint)要简单,这是由于可以使用分割掩码数据集和内绘模型来实现内绘。例如,你是一名图形设计师,需要在一张图片中添加一个特定的对象,比如一只戴着墨镜的狗。使用这项技术,你只需提供一条文本指令,如“在图片中添加一只戴着墨镜的狗”,系统就会自动在图片中添加这只狗,同时确保添加的对象与原图风格一致,位置和大小恰当。
- 项目主页:https://rotsteinnoam.github.io/Paint-by-Inpaint
- GitHub:https://github.com/RotsteinNoam/Paint-by-Inpaint
- Demo:https://huggingface.co/spaces/paint-by-inpaint/demo

主要功能:
- 文本驱动的图像编辑:根据用户的文本指令在图像中添加对象。
- 自动化数据集创建:自动生成包含图像及其对应去对象版本的大规模数据集。
主要特点:
- 逆向内绘过程:通过训练一个扩散模型来逆转内绘过程,从而在图像中添加对象。
- 自然目标图像:与其他编辑数据集不同,该数据集使用自然目标图像而非合成图像。
- 保持源图像和目标图像之间的一致性:通过构建过程自然地维持一致性。
工作原理:
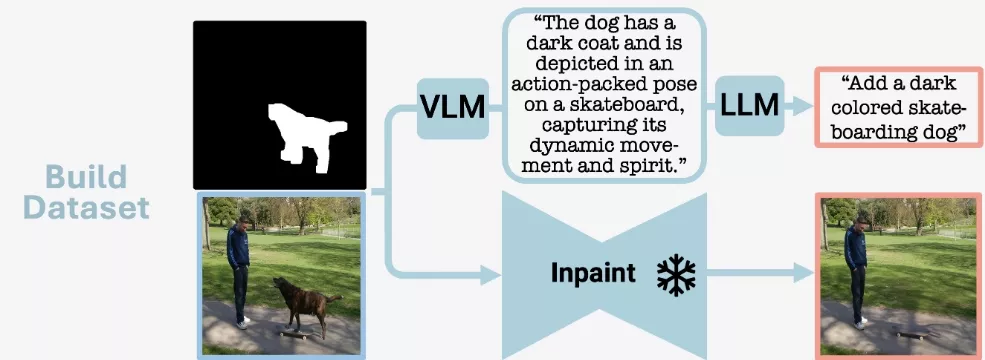
- 创建源图像和目标图像对:使用分割数据集和高性能的内绘模型,创建包含对象的图像和移除对象后的图像对。
- 生成添加指令:利用大型视觉-语言模型(VLM)和大型语言模型(LLM),为每对图像生成详细的自然语言添加指令。
- 模型训练:使用创建的数据集训练一个扩散模型,使其能够根据对象添加指令来编辑图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











