
扩散模型在文本到图像(T2I)和文本到视频(T2V)合成等生成任务中取得了显著成果。然而,在T2V生成中,实现准确的文本对齐仍然是一个具有挑战性的问题,尤其是在处理帧间复杂的时序依赖性时。现有的基于强化学习(RL)的方法通常需要可微分的奖励函数,或者受限于有限的提示,这阻碍了它们的可扩展性和适用性。
Free^2Guide:无梯度框架的提出
为了解决这些问题,韩国科学技术院的研究人员提出了一种新颖的无梯度框架 Free^2Guide,旨在将生成的视频与文本提示对齐,而无需额外的模型训练。Free2Guide通过利用路径积分控制原理,实现了无需梯度信息的黑盒大型视觉语言模型(Large Vision-Language Models,简称LVLMs)来指导视频生成过程,从而提高了文本到视频合成的准确性和视频质量。
例如,我们有一个文本提示:“一只快乐的熊猫在篝火旁弹吉他,背景是雪山”。使用Free2Guide框架,我们可以生成一个视频,其中不仅包含了文本描述的所有元素(熊猫、吉他、篝火、雪山),而且这些元素在视频中的动态表现(如熊猫弹吉他的动作)也与文本描述紧密对齐。
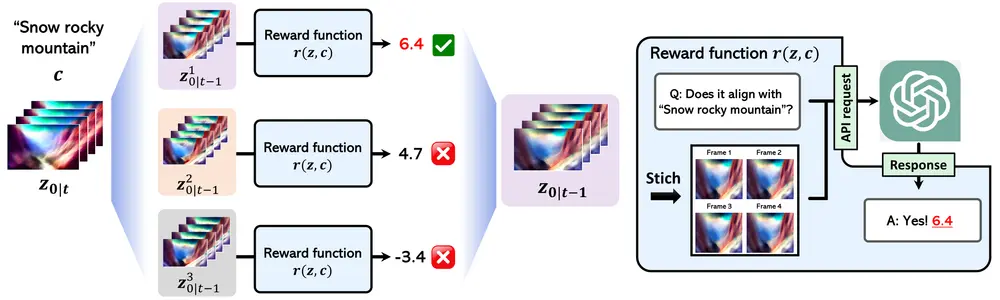
Free^2Guide 的主要特点如下:
- 无梯度优化:传统的基于RL的方法依赖于可微分的奖励函数,这限制了可以使用的奖励模型类型。Free^2Guide 则利用 路径积分控制原理,能够使用非可微分的奖励函数来指导扩散模型的生成过程。这意味着可以集成强大的黑箱大视觉语言模型(LVLMs)作为奖励模型,而无需担心其可微性问题。
- 灵活的奖励模型集成:Free^2Guide 支持灵活地集成多个奖励模型,包括大规模基于图像的模型。这些模型可以协同工作,以增强文本对齐效果,而不会产生显著的计算开销。通过结合不同类型的奖励模型,Free^2Guide 可以更好地捕捉视频中的多模态信息,从而提高生成视频的质量。
- 无需额外训练:与传统的RL方法不同,Free^2Guide 不需要对生成模型进行额外的训练。它直接利用现有的扩散模型和奖励模型,通过路径积分控制来调整生成过程。这种方法不仅简化了实现过程,还提高了框架的可扩展性和适用性。
技术细节
- 路径积分控制:Free^2Guide 基于路径积分控制原理,通过近似扩散模型的引导过程来实现文本对齐。具体来说,它通过采样多个生成路径,并根据奖励模型的评分选择最优路径,从而逐步优化生成结果。这种方法能够在不依赖梯度的情况下,有效地引导生成过程朝着更符合文本提示的方向发展。
- 非可微分奖励函数:由于路径积分控制不需要可微分的奖励函数,Free^2Guide 可以集成各种类型的奖励模型,包括那些无法提供梯度信息的黑箱模型。这使得研究人员可以充分利用现有的强大视觉语言模型(如CLIP、BLIP等),而不必担心其可微性问题。
- 多奖励模型协同工作:Free^2Guide 支持同时使用多个奖励模型,每个模型可以专注于不同的方面(如图像质量、文本对齐、动作一致性等)。通过加权组合这些模型的评分,Free^2Guide 可以在多个维度上优化生成视频的质量。此外,这种多模型集成方式不会显著增加计算开销,因为路径积分控制本身已经考虑了多个生成路径的并行计算。
工作原理
Free2Guide基于路径积分控制理论,通过以下步骤实现视频生成的指导:
- 视频潜在扩散模型(Video Latent Diffusion Model,简称VLDM):学习一个随机过程,通过迭代去噪生成连贯的视频序列。
- 指导扩散模型:在给定文本提示的条件下,使用反向时间随机微分方程(SDE)采样过程来检索干净的潜在表示。
- 路径积分控制:将扩散模型视为一个熵正则化的马尔可夫决策过程(MDP),并使用路径积分控制来估计最优控制,从而在不依赖奖励函数梯度的情况下指导视频生成。
实验结果
研究团队在多个基准数据集上进行了广泛的实验,评估了 Free^2Guide 在文本对齐和生成视频质量方面的表现。实验结果表明:
- 文本对齐效果显著提升:Free^2Guide 在各个维度上显著提高了文本对齐的效果,生成的视频更加符合文本提示的要求。
- 生成视频质量增强:除了文本对齐外,Free^2Guide 还增强了生成视频的整体质量,包括图像清晰度、动作连贯性和内容一致性等方面。
- 计算效率高:由于无需额外训练且支持多奖励模型协同工作,Free^2Guide 在保持高质量生成的同时,具有较高的计算效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











