来自麻省理工、微软、Adobe和谷歌的研究团队推出创新框架FeatUp,它能够提高深度学习模型中图像特征的空间分辨率,而不会损失原有的语义信息。在计算机视觉领域,深度学习模型通常会从图像中提取特征,这些特征有助于完成各种任务,比如物体识别、图像分割等。但是,这些特征往往因为模型的设计而缺乏足够的空间分辨率,导致无法直接用于需要高分辨率的密集预测任务,比如精确的物体边界识别。
FeatUp是一个与任务和模型无关的框架,旨在恢复深度特征中丢失的空间信息。团队提出了FeatUp的两种变体:一种是在单次前向传递中利用高分辨率信号引导特征,另一种是对单张图像拟合一个隐式模型,以重建任意分辨率的特征。这两种方法都使用了与NeRFs相似的深度类比多视图一致性损失。FeatUp的特征保留了原始语义,可以替换到现有应用中,即使在未重新训练的情况下也能提高分辨率和性能。
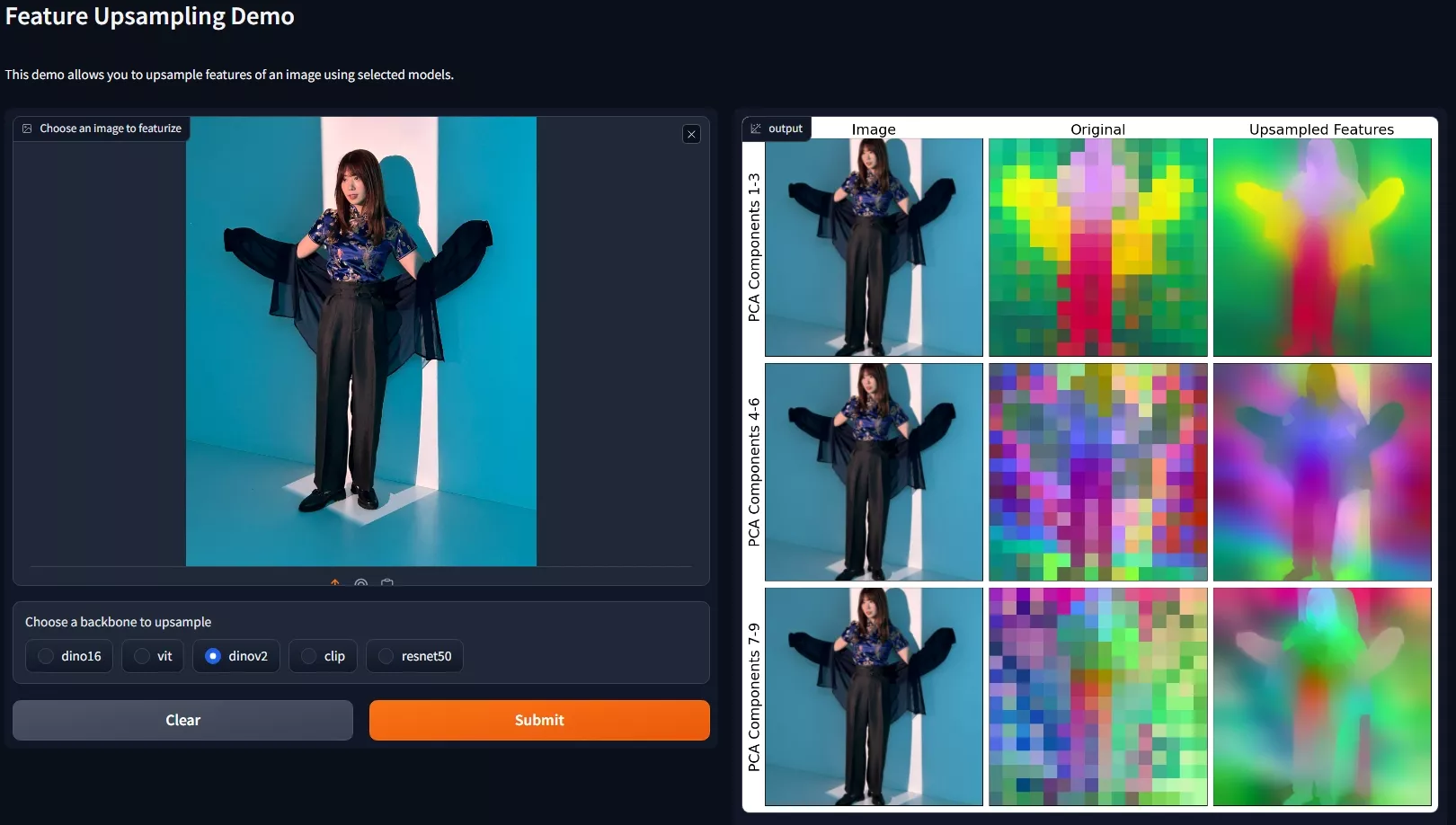
主要功能和特点:
- 多模型通用性:FeatUp是一个任务和模型无关的框架,意味着它可以与任何现有的深度学习模型配合使用,提高其特征的空间分辨率。
- 高分辨率特征:通过FeatUp,可以在不改变原有特征语义的前提下,恢复丢失的空间信息,生成高分辨率的特征。
- 性能提升:使用FeatUp后的特征可以在多种下游任务中提升性能,包括类别激活映射生成、图像分割和深度估计等。
- 快速CUDA实现:FeatUp中的一个关键组件——联合双边上采样(Joint Bilateral Upsampling, JBU)——通过高效的CUDA实现,大幅提升了计算速度和内存效率。
工作原理:
FeatUp的工作原理灵感来自于3D重建技术NeRF。它通过对输入图像进行微小变换(如翻转、填充、裁剪等),生成多个低分辨率的特征视图。然后,通过多视图一致性损失(multi-view consistency loss)和深度类比技术,训练一个上采样网络,将这些低分辨率视图聚合成高分辨率特征。FeatUp提供了两种上采样的变体:一种是单次前向传播中引导特征的上采样网络,另一种是针对单个图像拟合隐式模型以重建任意分辨率的特征。
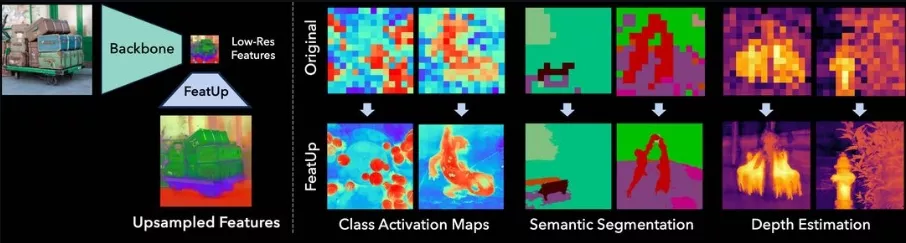
具体应用场景:
- 图像分割:在自动驾驶车辆的视觉系统中,需要对道路、行人、车辆等进行精确分割。使用FeatUp可以提高分割的精确度,尤其是在物体边缘区域。
- 医学图像分析:在处理医学图像时,高分辨率特征可以帮助医生更准确地识别病变区域,提高诊断的准确性。
- 图像编辑和合成:在图像编辑软件中,FeatUp可以用来提高图像编辑工具的性能,如在保持细节的同时放大图像。
- 增强现实(AR):在AR应用中,需要实时处理和分析用户周围的环境。FeatUp能够提供更高分辨率的视觉特征,从而改善AR体验。
FeatUp是一个强大的工具,它通过提升深度学习模型中特征的空间分辨率,为各种需要高分辨率图像理解的任务提供了支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











