
来自特拉维夫大学和Snap的研究人员推出Bounded Attention,它旨在解决文生图模型在生成包含多个主题(subjects)的图像时遇到的挑战。这些模型通常难以准确地捕捉到复杂输入提示中的意图语义,尤其是当输入提示包含多个语义或视觉上相似的主题时。
例如,如果用户想要生成一张图片,其中包含“三只穿着不同衣服的小猫和两只灰色的小狗在楼梯上”,Bounded Attention可以帮助模型准确地生成每只小猫和小狗,确保它们的颜色和位置与用户的描述相匹配,而不会相互混淆或融合。这样,生成的图像将更好地反映用户的意图,每个主题都能保持其独特性。

主要功能和特点:
- 控制布局: Bounded Attention通过限制注意力机制,允许用户对生成图像中的主题进行更精确的控制。
- 减少语义泄露: 通过在采样过程中限制信息流,该方法减少了不同主题间不应有的语义混合。
- 无需训练: Bounded Attention是一种无需训练的方法,可以直接应用于现有的文本到图像扩散模型。
- 保持主题个性: 该方法鼓励每个主题保持其独特性,即使在复杂的多主题条件下也能生成高质量的图像。
工作原理:
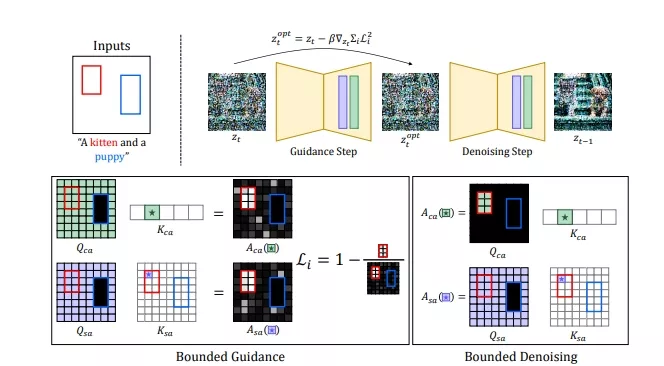
Bounded Attention通过在注意力层中引入一个掩码(mask),这个掩码可以阻止无关的视觉和文本标记对每个像素的影响,从而减少主题间的信息泄露。在生成过程中的早期阶段,使用Bounded Guidance步骤通过梯度下降法优化潜在信号,使其与输入布局更好地对齐。在后续阶段,应用Bounded Denoising步骤,通过细化的掩码来减少语义泄露,并保持图像的细节质量。
具体应用场景:
- 创意内容生成: 艺术家和设计师可以使用Bounded Attention来创建包含多个主题的复杂场景,例如,生成一张包含不同种类动物的丛林画面。
- 个性化图像编辑: 用户可以通过指定布局和主题来生成个性化的图像,例如,定制一张包含特定宠物和家具的家居场景图片。
- 教育和游戏: 在教育软件或游戏中,Bounded Attention可以用来生成教学材料或游戏关卡中的多个对象,确保每个对象都符合描述且不相互混淆。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











