
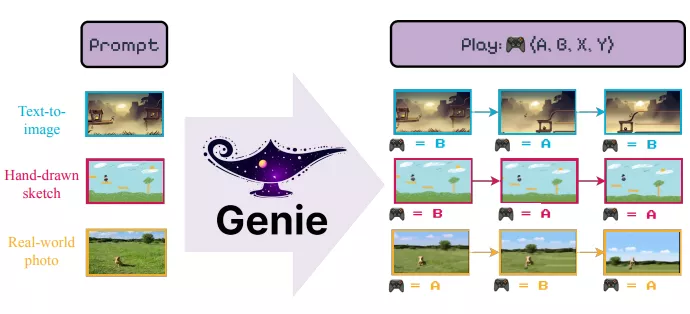
来自不列颠哥伦比亚大学和Google DeepMind研究人员提出创新人工智能系统Genie,它能够从互联网上的未标记视频数据中学习,生成可交互的虚拟环境。Genie的核心功能是将文本、合成图像、照片甚至手绘草图转换成可以探索的互动式游戏世界。这个系统拥有110亿个参数,可以被视为一个基础世界模型。
内容创作者和游戏开发者可以使用Genie快速原型设计和实现他们的创意。通过结合最先进的文本到图像生成模型,例如Imagen2,他们可以将文本描述转换成图像,然后使用Genie为这些图像赋予交互性和可玩性。这种方法降低了创造复杂虚拟环境的门槛,使得创意实现变得更加容易和快速。
主要功能:
- 将各种提示(如文本、图像等)转换成互动环境。
- 允许用户在生成的环境中逐帧进行操作。
- 通过学习潜在的动作空间,模仿未见过视频中的行为。
主要特点:
- 无需地面真实动作标签或其他特定领域要求即可进行训练。
- 能够从单一文本或图像提示生成互动环境。
- 通过潜在动作模型,用户可以控制视频生成过程。
工作原理:
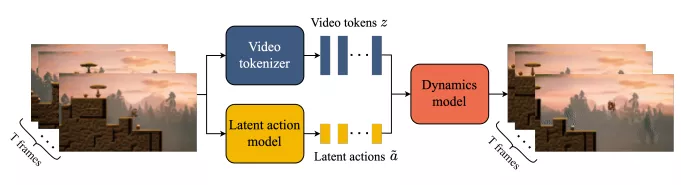
Genie的工作原理基于三个关键组件:潜在动作模型(LAM)、视频标记器和动态模型。首先,潜在动作模型从视频中学习潜在动作,这些动作代表了视频中的变化。然后,视频标记器将原始视频帧转换成离散的标记。最后,动态模型结合潜在动作和过去的视频标记来预测下一帧。
应用场景:
- 游戏开发:Genie可以用来快速生成游戏环境,为游戏设计师提供灵感。
- 教育和培训:在教育领域,Genie可以创建互动的学习环境,帮助学生更好地理解复杂概念。
- 娱乐和创意:艺术家和内容创作者可以使用Genie来创造独特的视觉作品和故事。
- 机器人和自动化:Genie的潜在动作模型可以用于训练机器人,使它们能够在模拟环境中学习新技能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











