
随着扩散模型的迅速发展,视频合成技术尤其是可控视频生成领域取得了重大突破,这对自动驾驶等应用具有重要意义。然而,现有的视频生成方法在处理高分辨率和长视频时面临可扩展性和控制条件整合的挑战,限制了它们在实际自动驾驶场景中的应用。
MagicDriveDiT的提出
为了解决这些问题,香港中文大学、香港科技大学、华为云和华为诺亚方舟实验室的研究人员联合开发了一种名为MagicDriveDiT的新方法。该方法基于DiT(Diffusion in Time)架构,旨在提高视频合成的效率和可控性,以更好地服务于自动驾驶应用。
例如,自动驾驶公司需要测试其感知系统在不同天气条件下的性能。使用MagicDriveDiT,可以生成一系列高分辨率的视频,模拟晴天、雨天以及夜间的交通场景。这些视频不仅分辨率高,而且帧数足够长,能够提供丰富的测试数据,帮助工程师评估和优化自动驾驶系统在各种条件下的表现。通过这种方式,MagicDriveDiT为自动驾驶技术的发展提供了一个强大的工具。
主要功能和特点
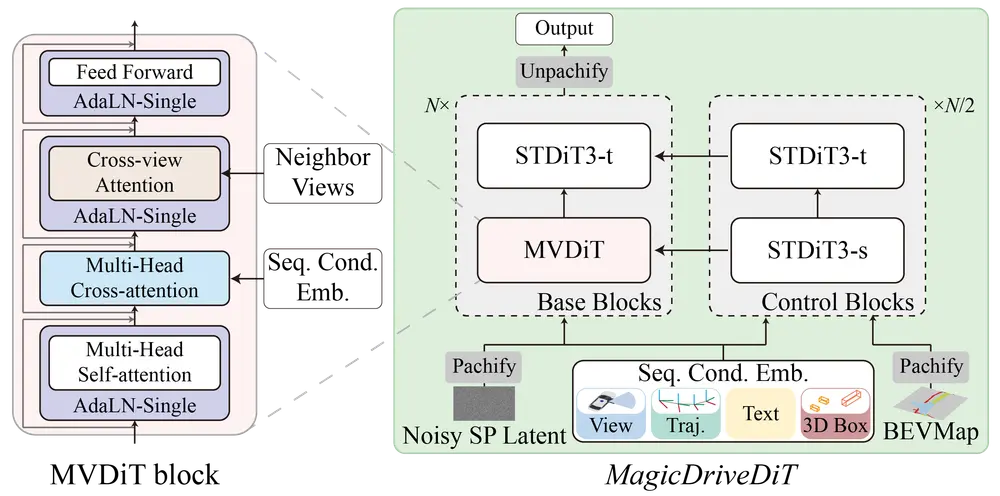
高分辨率和长视频生成:MagicDriveDiT能够生成高分辨率(如848×1600像素)和长帧数(最多241帧)的视频,这在以往的方法中是难以实现的。 精确控制:通过空间-时间条件编码,MagicDriveDiT能够精确控制视频中的空间和时间潜在表示,从而实现对视频内容的精细控制。 渐进式训练策略:该方法采用从短到长视频的渐进式训练策略,使模型能够逐步学习并处理更复杂的场景。 多分辨率和时长训练:通过混合不同分辨率和时长的视频进行训练,增强了模型的泛化能力,使其能够生成超出训练设置的分辨率和帧数的视频。
核心技术特点
流匹配增强可扩展性:MagicDriveDiT采用了流匹配技术,显著提高了模型处理大规模视频数据的能力,使其能够生成更长、更高分辨率的视频内容。 渐进式训练策略:为了应对复杂场景的挑战,MagicDriveDiT引入了渐进式训练策略,逐步增加视频的分辨率和长度,从而保证训练过程的稳定性和最终生成视频的质量。 时空条件编码:通过整合时空条件编码,MagicDriveDiT实现了对视频生成过程中时空潜在变量的精确控制,确保生成的视频不仅真实而且符合特定的控制条件。
工作原理
MagicDriveDiT的工作原理包括以下几个关键步骤:
流匹配(Flow Matching):使用流匹配公式来提高扩散模型的训练和推理效率。 空间-时间条件编码:为了实现对空间-时间潜在变量的精确控制,特别设计了空间-时间条件编码。 多视图一致性:通过交叉视图注意力层(cross-view attention layer)来增强多视图生成的一致性。 渐进式引导训练:从低分辨率图像开始训练,逐步过渡到高分辨率长视频,以加速模型收敛并提高控制能力。
实验结果
实验结果显示,MagicDriveDiT在生成高分辨率和长帧数的真实街道场景视频方面表现出色。无论是视频的质量还是时空控制的精度,MagicDriveDiT都显著优于现有的方法。这些成果为自动驾驶领域的各种任务提供了强有力的技术支持,包括但不限于环境感知、路径规划和决策制定等。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











