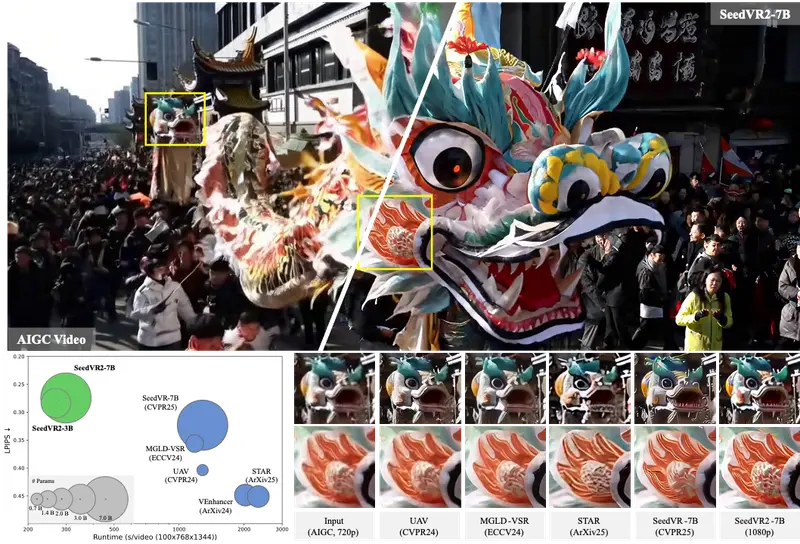
新加坡国立大学学习与视觉实验室的研究人员推出新型图像生成模型LinFusion,它能够利用文本提示生成高分辨率的图像。LinFusion的核心在于它采用了一种新颖的线性注意力机制,这使得它在处理大量像素时具有线性复杂度,从而有效地提高了生成图像的效率。此外,它与预训练的SD组件(如ControlNet和IP-Adapter)高度兼容,不需要额外的适应工作。
- 项目主页:https://lv-linfusion.github.io
- GitHub:https://github.com/Huage001/LinFusion
- 模型地址:https://huggingface.co/Yuanshi/LinFusion-1-5
例如,你是一名游戏设计师,需要为一款即将推出的游戏设计一个具有未来主义风格的城市场景。你可以向LinFusion输入文本提示,如“未来城市,夜晚,霓虹灯光,高分辨率”,模型将根据这个描述生成一张详细的、高分辨率的城市夜景图像,这可以大大加速游戏美术的创作过程。

主要功能:
- 根据文本描述生成高分辨率的图像。
- 支持零样本(zero-shot)跨分辨率生成,即在训练时未见过的分辨率上也能生成图像。
主要特点:
- 线性复杂度:与传统的基于Transformer的模型相比,LinFusion在处理像素时的复杂度是线性的,而不是平方级的,这显著降低了计算资源的需求。
- 高兼容性:LinFusion能够与多种预训练的模型组件(如ControlNet和IP-Adapter)无缝配合,无需额外训练。
- 跨分辨率生成:模型能够在不同的分辨率下生成图像,包括在训练过程中未见过的高分辨率。
工作原理:
LinFusion采用了一种称为“广义线性注意力”的机制,它通过以下步骤工作:
- 文本处理:首先将文本提示输入模型,模型通过预训练的编码器提取文本特征。
- 注意力机制:使用线性注意力机制处理图像数据,这种机制可以有效地处理大量像素,同时保持计算效率。
- 知识蒸馏:通过知识蒸馏技术,将预训练的Stable Diffusion模型的知识转移到LinFusion中,使得LinFusion在训练时能够快速学习并达到优异的性能。
- 生成图像:通过迭代去噪过程,逐步从噪声中恢复出清晰的图像。
具体应用场景:
- 艺术创作:艺术家和设计师可以使用LinFusion根据文本描述生成高分辨率的艺术作品。
- 游戏开发:在游戏设计中,LinFusion可以用来快速生成游戏场景或角色的概念图。
- 虚拟现实:在虚拟现实内容的创建中,LinFusion可以帮助生成逼真的背景图像或环境。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











