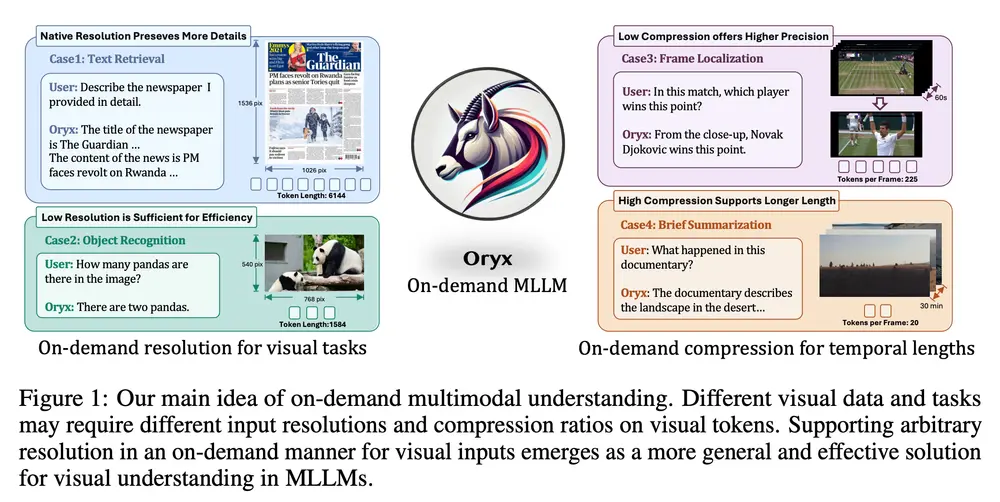
清华大学、腾讯和南洋理工大学 S-Lab的研究人员推出多模态大语言模型Oryx,它专门设计用于理解和处理视觉数据,如图像、视频和3D场景。Oryx模型的特点是能够根据需要处理任意空间大小和时间长度的视觉输入,这使得它在处理不同分辨率和时长的视觉内容时既高效又灵活。例如,你给Oryx模型一个关于野生动物的长视频,它可以帮你总结出视频中的关键事件,比如动物的迁徙行为,或者识别视频中出现的特定物种。同样,对于一系列3D扫描图像,Oryx可以识别出不同视角下相同的物体,帮助构建更完整的3D空间理解。
- GitHub:https://github.com/Oryx-mllm/Oryx
- 模型:https://huggingface.co/collections/THUdyh/oryx-66ebe5d0cfb61a2837a103ff
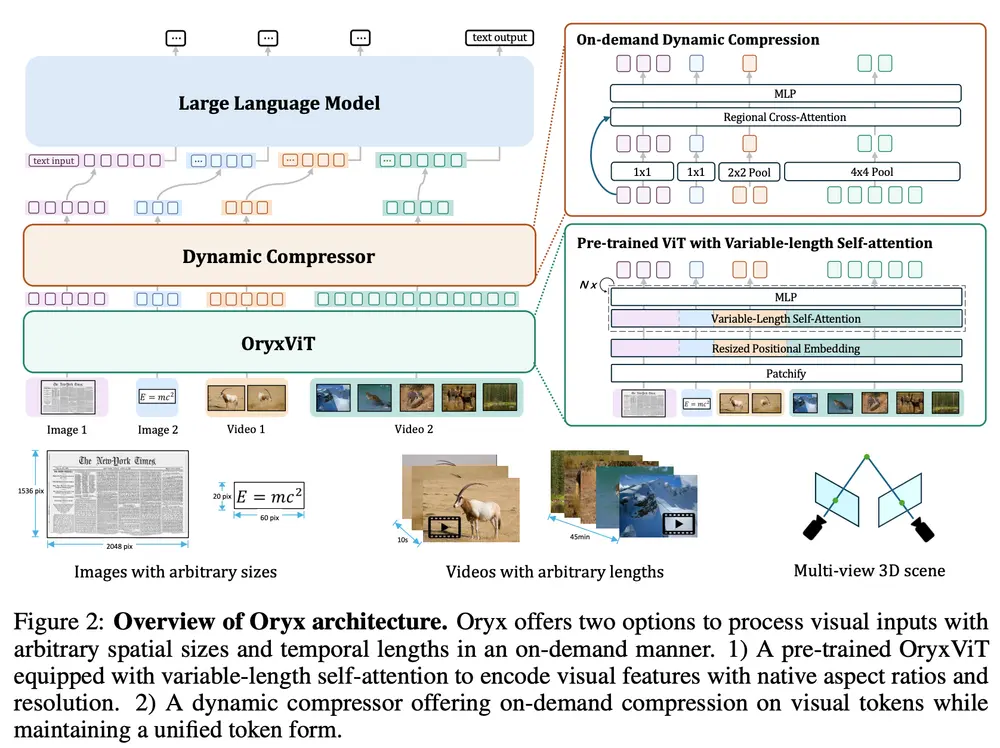
Oryx是一种统一的多模态架构,用于图像、视频和多视角 3D 场景的空间和时间理解。Oryx 通过两项核心技术创新提供按需解决方案,无缝高效地处理任意空间尺寸和时间长度的视觉输入:1)预训练的 OryxViT 模型,能够将图像以任意分辨率编码为 LLM 友好的视觉表示;2)动态压缩模块,支持按需进行 1 倍到 16 倍的视觉标记压缩。这些设计特性使得 Oryx 能够处理极长的视觉上下文,如视频,采用较低分辨率和高压缩比的同时,保持高识别精度,适用于如文档理解等任务,保持原分辨率且不压缩。除了架构改进外,增强的数据管理和专门针对长上下文检索和空间感知数据的训练也有助于 Oryx 同时在图像、视频和 3D 多模态理解方面实现强大的能力。
主要功能和特点:
- 任意分辨率处理: Oryx模型可以使用预训练的OryxViT模型将不同分辨率的图像编码成适合大型语言模型处理的视觉表示。
- 动态压缩模块: 支持对视觉令牌进行1倍到16倍的动态压缩,以适应不同的视觉内容长度,例如短图像或长视频。
- 多模态理解: 能够同时处理图像、视频和3D数据,提供强大的空间和时间理解能力。
- 开源: Oryx模型是开源的,这意味着研究人员和开发者可以自由访问和使用这个模型。
工作原理:
Oryx模型通过以下几个关键步骤工作:
- 视觉编码: 使用OryxViT对输入的视觉数据进行编码,这个编码过程可以处理任意分辨率的图像,保留了图像的原始信息。
- 动态压缩: 根据视觉内容的长度,动态调整压缩比例,以优化处理效率。例如,对于长视频,模型可以降低分辨率并进行压缩,而对于短图像,则可以保持较高分辨率。
- 联合训练: 通过结合图像、视频和3D数据的训练,Oryx模型能够学习到丰富的视觉和语言特征,提高其在多模态任务上的性能。
具体应用场景:
- 视频理解: 可以用于分析和理解视频内容,比如自动生成视频摘要或回答有关视频内容的问题。
- 图像识别: 能够识别和描述图像中的对象和场景,适用于图像检索或自动化图像标注。
- 3D场景理解: 在3D建模和虚拟现实等领域,Oryx可以帮助理解和解释3D空间中的对象和关系。
- 文档分析: 对于包含大量视觉元素的文档,Oryx可以提供更深入的内容理解,比如自动识别文档中的关键信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











