在影视制作、游戏开发和多媒体内容创作中,为视频添加恰当的音效是提升观众体验的重要环节。然而,创造既符合视觉场景又具有艺术感的音效往往需要耗费大量时间和专业技能。为了应对这一挑战,密歇根大学与Adobe研究中心的研究人员共同开发了MultiFoley——一种创新的视频引导音效生成模型,它能够根据多种模态的控制信号(包括文本、音频和视频)来生成与视频同步的声音效果。这项技术特别适用于影视后期制作中的声音设计,即Foley艺术,它通过创造与视觉内容相匹配的声音来增强观众的体验。
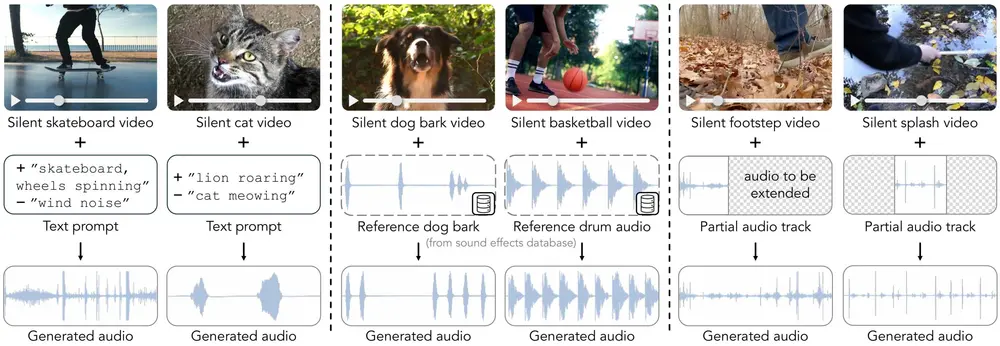
例如,有一个视频片段,内容是一个人在打篮球,但是没有声音。使用MultiFoley,可以通过提供文本提示(比如“篮球击地声”)或者参考音频(比如另一个篮球击地的声音样本),来生成与视频动作同步的声音效果。甚至可以更有创意地将篮球击地声替换成鼓声,或者将狮子的吼叫声变成猫的喵喵声。
主要特点:
- 多模态控制:整合了文本、音频和视频条件信号,提供更细致的声音设计控制。
- 高质量音频生成:通过在互联网视频数据集和专业声音效果库上的训练,能够生成符合专业标准的全频带(48kHz)音频。
- 灵活的应用:支持文本控制的Foley生成、音频控制的Foley生成和Foley音频扩展等多种应用。
多模态条件控制
MultiFoley的最大特点在于其灵活性和多模态交互能力:
- 文本提示:用户可以通过简单的文本描述来指导音效生成。例如,可以指定创建“滑板轮子旋转的声音,但不带风噪”,或是将“狮子的咆哮声变得像猫的喵喵叫”。
- 参考音频:用户可以从现有的音效库或部分视频片段中选择参考音频,以实现更加精确的音效匹配和个性化定制。
- 视频引导:MultiFoley能够根据无声视频的内容自动生成同步的高质量音效,确保声音与画面完美契合。
关键技术创新
MultiFoley的核心优势在于其独特的训练方法和技术架构:
- 联合训练:该模型同时使用互联网上的视频数据集和专业的SFX录音进行训练。这种联合训练方式不仅提高了音效的真实性和多样性,还使得模型能够在不同的条件下生成高质量的全频带(48kHz)音频。
- 高质量音频生成:通过优化的神经网络结构,MultiFoley能够生成高保真度的音效,满足专业级别的需求。无论是自然环境音还是奇幻效果音,都能得到逼真的再现。
工作原理:
MultiFoley模型基于扩散变换器(diffusion transformer)和高质量的音频自动编码器,结合了一个冻结的视频编码器来实现音频-视频同步。它通过以下步骤工作:
- 编码输入:将输入的沉默视频、文本提示和参考音频-视觉对编码成特征表示。
- 扩散过程:在潜在空间中逐渐添加高斯噪声到干净的音频潜在代码中。
- 逆向去噪:通过迭代去噪过程,从噪声中恢复出干净的音频潜在代码。
- 解码生成:将最终的干净音频潜在代码解码成波形,生成与视频同步的声音效果。
性能验证
为了评估MultiFoley的实际表现,研究人员进行了自动化评估和人类研究。结果显示,无论是在同步性、音质还是创意表达方面,MultiFoley都显著优于现有方法。这表明,MultiFoley不仅可以大幅简化音效创作流程,还能为创作者提供更多的创意自由。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











