
来自Leonardo AI的研究人员推出ToDo(Token Downsampling),它是为了提高高分辨率图像生成的效率而设计的。这种方法主要是为了解决图像扩散模型在处理大图像时面临的时间和内存限制问题,同时尽量不影响图像的质量和细节。
在图像生成领域,尤其是使用扩散模型时,计算复杂度通常是一个问题,因为它们需要处理大量的数据。ToDo方法通过减少在生成过程中需要处理的数据量来加速图像生成,同时尽量保持图像质量。
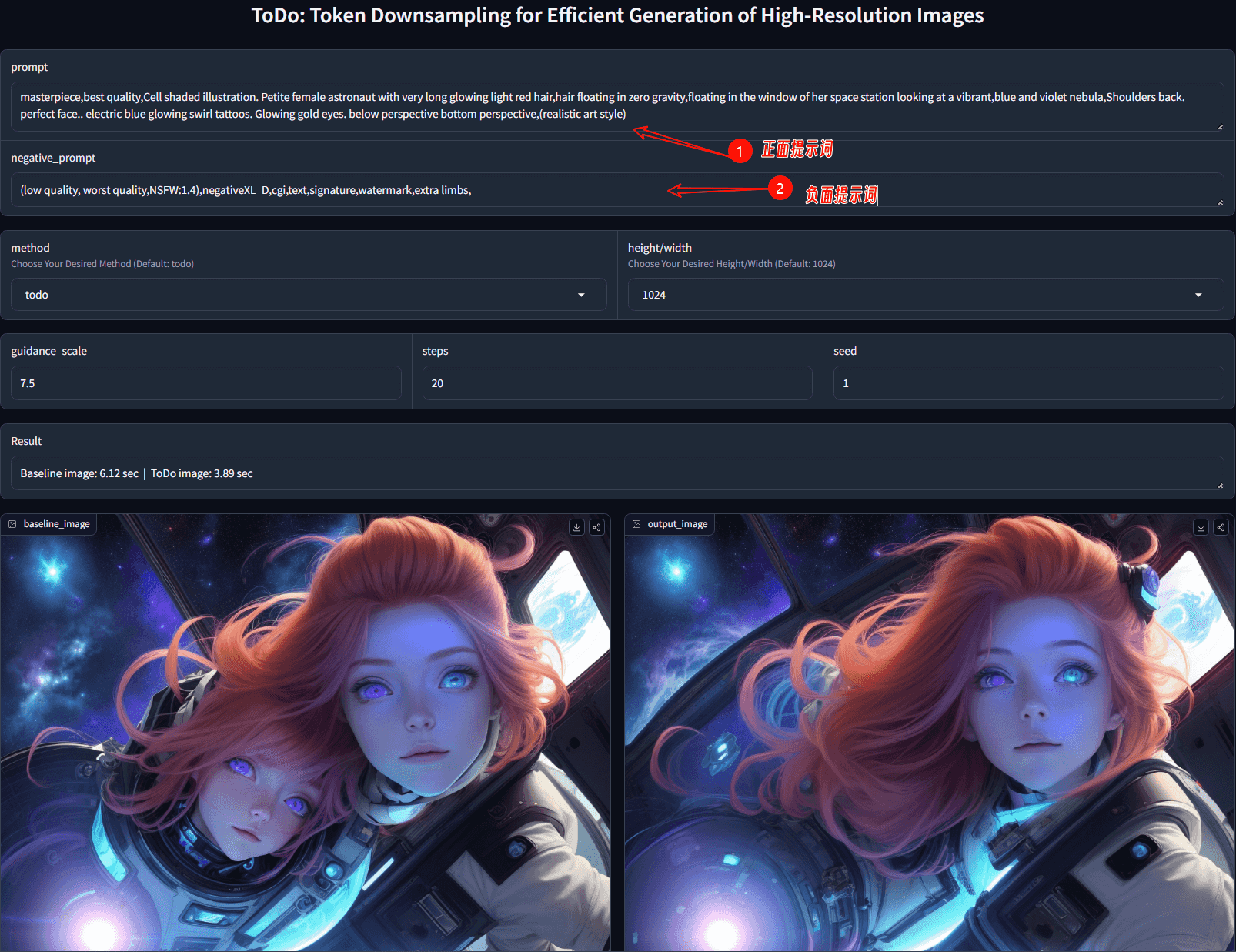
主要功能:
- 加速图像生成:ToDo方法可以显著提高生成高分辨率图像的速度,例如在2048×2048分辨率下,可以将推理速度提高2倍甚至更多。
- 保持图像质量:尽管减少了计算量,但ToDo方法仍然能够保持生成图像的细节和质量。
主要特点:
- 无需训练:ToDo方法是一种训练后的方法,这意味着它可以直接应用于现有的模型,而不需要对模型进行重新训练。
- 空间连续性:该方法利用图像中相邻像素通常具有相似值的特性,通过空间连续性来简化合并过程,减少了计算负担。
- 改进的注意力机制:ToDo方法在保留查询完整性的同时,对注意力机制中的键(keys)和值(values)进行下采样,以减少参与注意力计算的矩阵的维度。
工作原理:
ToDo方法的核心是观察到图像中的相邻像素往往具有相似的值。基于这一点,它采用了一种下采样技术,类似于图像处理中的网格子采样。这种方法通过最近邻算法来合并空间上接近的标记(tokens),而不是计算所有标记之间的相似度。此外,ToDo还改进了注意力机制,通过在注意力计算中应用下采样操作,同时保留原始的查询标记,以此来减少计算量并保持图像质量。
应用场景:
- 高分辨率图像生成:ToDo方法特别适合于需要快速生成高分辨率图像的场景,例如在游戏开发、电影特效制作或者虚拟现实等领域。
- 优化现有模型:对于那些已经训练好的扩散模型,ToDo方法可以作为一种优化手段,提高模型的推理速度,使其更适合实时应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











