
现有的前馈图像到3D的方法主要依赖于2D多视图扩散模型,这些模型在生成3D内容时存在一些显著的局限性。首先,它们无法保证3D一致性,导致在改变提示视图方向时容易崩溃。其次,这些方法主要处理以物体为中心的提示图像,限制了其应用场景。
DiffusionGS的提出
为了解决这些问题,约翰霍普金斯大学、Adobe 研究中心和香港科技大学的研究人员共同提出了一种新的单阶段3D扩散模型——DiffusionGS,用于从单视图图像生成3D对象和场景。该模型能够在单视图条件下生成高质量的物体和场景,并且在不同视角下的表现更加稳健。
- 项目主页:https://caiyuanhao1998.github.io/project/DiffusionGS
- GitHub:https://github.com/caiyuanhao1998/Open-DiffusionGS
例如,你是一名电影制作人,需要将一张历史照片中的静态场景转换为3D模型以重建历史事件。使用DiffusionGS,你可以上传该照片,并生成一个3D场景,包括人物、建筑和其他细节。这个3D场景不仅可以用于电影的视觉特效,还可以用于虚拟现实体验,让观众能够身临其境地体验历史事件。

主要功能和特点
单视图3D生成:DiffusionGS能够从单个视角的2D图像生成3D对象和场景。 直接3D高斯点云输出:在每个时间步直接输出3D高斯点云,增强了视图一致性。 快速可扩展的单阶段生成:DiffusionGS具有快速推理速度,大约6秒内即可在单个A100 GPU上生成一个资产,并且可以轻松应用于大型场景。 场景-对象混合训练策略:通过开发场景-对象混合训练策略,扩大了3D训练数据的规模,提高了模型的泛化能力。 新的相机条件编码方法:提出了一种新的相机条件编码方法,称为参考点Plücker坐标(RPPC),以更好地感知深度和3D几何信息。
工作原理
DiffusionGS的工作原理基于以下步骤:
扩散过程:使用去噪扩散概率模型(DDPM)逐步将真实数据分布转化为标准正态分布。 3D高斯点云预测:设计去噪器直接预测像素对齐的3D高斯,并在每个时间步进行监督。 混合训练策略:通过控制所选视图、相机条件、高斯点云和成像深度的分布,使模型适应对象和场景数据集。 参考点Plücker坐标(RPPC):使用每个射线上最接近世界坐标系原点的点作为参考点,提供关于射线位置和相对深度的更多信息。 双高斯解码器:根据对象和场景级别的数据集调整深度范围,使用两个MLP来解码对象和场景的高斯原语。
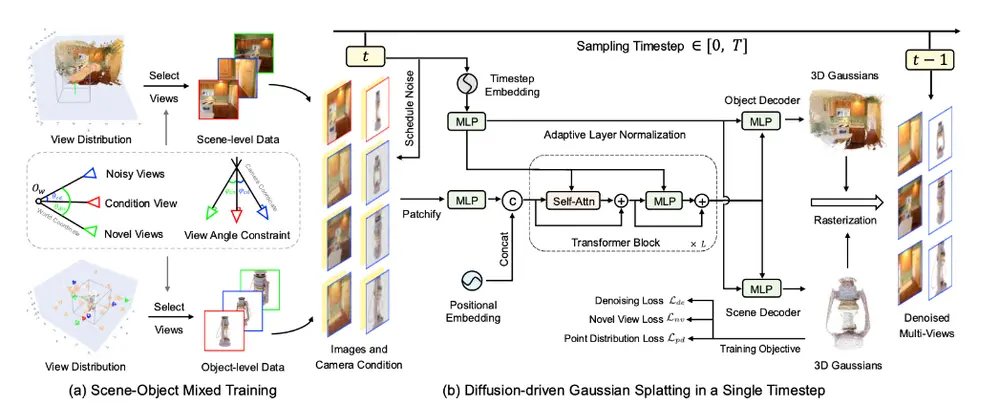
核心技术特点
直接输出3D高斯点云:DiffusionGS在每个时间步直接生成3D高斯点云,这种方法不仅确保了视图的一致性,还允许模型在给定任意方向的提示视图时生成稳定的结果,而不仅仅局限于物体中心的输入。 场景-物体混合训练策略:为了提高模型的生成能力和泛化能力,研究人员开发了一种场景-物体混合训练策略,通过扩展3D训练数据,使模型能够更好地处理多样化的输入。
实验结果
实验结果表明,DiffusionGS在多个方面显著优于现有的方法:
生成质量:在PSNR(峰值信噪比)指标上提高了2.20 dB,FID(Fréchet Inception Distance)指标降低了23.25。 生成速度:在A100 GPU上,DiffusionGS仅需约6秒即可完成生成任务,速度提高了5倍以上。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











