
浙江大学和阿里巴巴的研究人员推出新型视频生成框架MovieDreamer,专门用于制作长篇视频内容,比如电影。与传统的短时视频生成技术不同,MovieDreamer能够处理复杂的叙事结构和情节发展,同时保持角色和场景的连贯性。它结合了自回归模型的优势与基于扩散的渲染技术,开创了具有复杂情节进展和高视觉保真度的长时长视频生成领域。
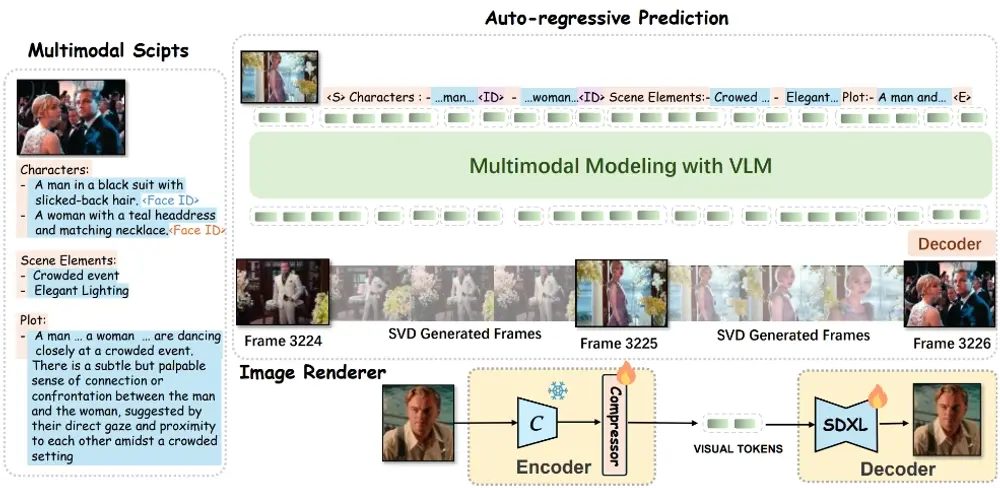
MovieDreamer利用自回归模型确保整体叙事的一致性,预测视觉令牌序列,并通过扩散渲染将其转换为高质量的视频帧。这种方法类似于传统的电影制作流程,在这种流程中复杂的故事情节被分解为易于管理的场景捕捉。此外,我们采用了一种多模态剧本,该剧本通过详细的字符信息和视觉风格丰富了场景描述,从而增强了不同场景之间的连续性和角色身份。

例如,你想要制作一部科幻电影的预告片,描述了一个穿着太空服的宇航员在火星表面探索的场景。使用MovieDreamer,你只需要提供一个文本脚本,包括角色描述、场景元素和情节概要。MovieDreamer将根据这些信息生成一系列视觉连贯的关键帧,然后这些帧将被转换成一段视频,展示宇航员在火星上的冒险旅程。这个过程不需要实际拍摄,大大降低了制作成本和时间,同时保持了视频内容的高质量和叙事深度。
主要功能
- 长篇视频生成:MovieDreamer能够生成具有复杂情节和高视觉保真度的长篇视频。
- 层次化叙事一致性:通过自回归模型确保全局叙事一致性,例如角色身份、道具和电影风格。
- 高质量视觉渲染:使用扩散模型将视觉令牌转换为高质量的视频帧。
主要特点
- 层次化框架:结合了自回归模型和基于扩散的渲染技术。
- 多模态脚本:丰富场景描述,包括详细的角色信息和视觉风格。
- 个性化生成:支持零样本和少样本个性化生成场景,适应不同长度的关键帧预测。
工作原理
- 关键帧令牌化:使用扩散自编码器将关键帧编码为紧凑的视觉令牌。
- 自回归预测:使用自回归模型预测视觉令牌序列,该模型基于多模态脚本和历史信息进行预测。
- 身份保持渲染:通过改进扩散解码器,增强角色身份保持能力,即使在复杂场景转换中也能保持角色的一致性。
- 视频生成:根据预测的关键帧使用图像到视频的扩散模型生成完整的视频序列。
具体应用场景
- 电影制作:MovieDreamer可以用于电影行业的长篇视频内容创作,降低制作成本和时间。
- 虚拟现实:在虚拟现实环境中生成长篇、连贯的叙事视频,提升用户体验。
- 教育和培训:生成长篇教育视频,提高学习内容的丰富性和吸引力。
- 娱乐和游戏:用于生成游戏内的视频内容或作为动画和故事叙述的一部分。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











