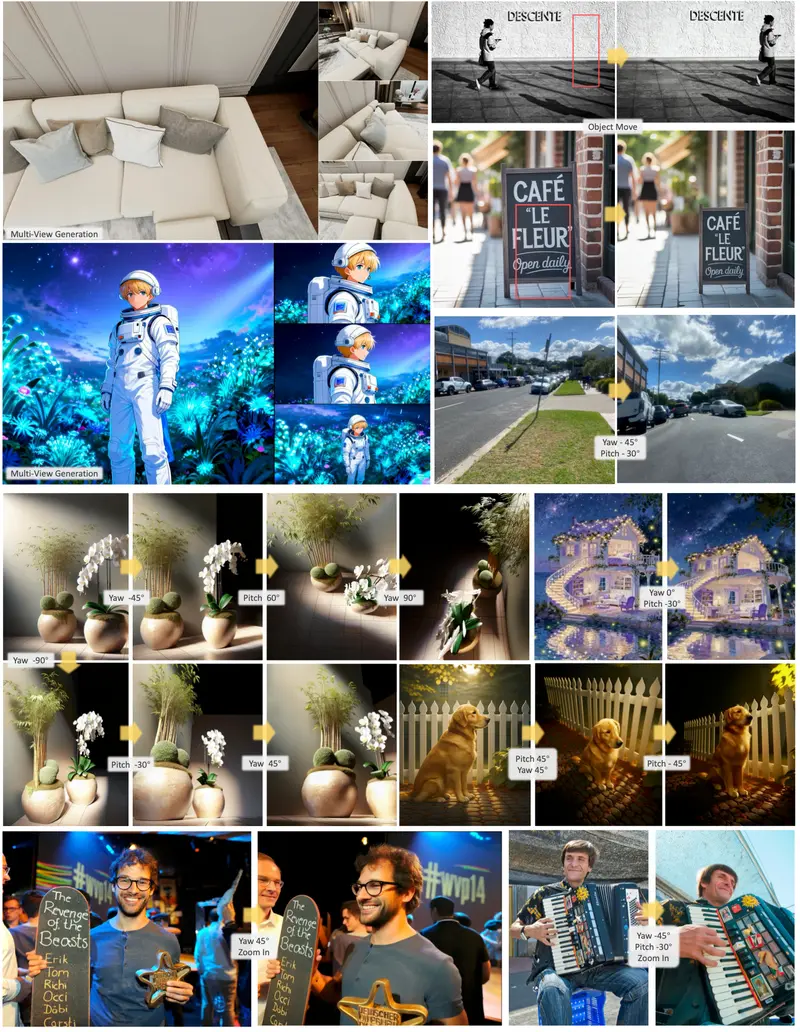
最近的文生视频模型在生成高质量视频方面取得了显著进展,但这些模型生成的视频往往与文本提示存在不对齐的情况,尤其是在处理包含多个对象和属性的复杂场景时。为了解决这一问题,北卡罗来纳大学教堂山分校的研究人员提出了VideoRepair,这是一个新颖的、与模型无关的、无需训练的视频细化框架。VideoRepair能够自动识别细粒度的文本-视频不对齐问题,并生成明确的空间和文本反馈,使得文生视频模型能够执行有针对性的、局部的细化,尤其是在文本描述复杂场景时。
例如,我们有一个文本提示:“A camel lounging in front of a snowman”,使用标准的T2V模型可能会生成一个骆驼,但是没有雪人。VIDEOREPAIR框架能够识别这种错位,并在视频中添加缺失的雪人,从而更准确地匹配文本提示。

主要功能:
视频评估(Video Evaluation):通过生成细粒度的评估问题并用机器学习语言模型(MLLM)回答这些问题,来检测视频中的错位。 精细化规划(Refinement Planning):识别视频中准确生成的对象,并为需要精细化的其他区域创建局部提示。 区域分解(Region Decomposition):使用结合的定位模块来分割视频中需要保留和精细化的区域。 局部精细化(Localized Refinement):在保留正确生成区域的同时,重新生成视频以调整错位区域。
主要特点:
模型无关性:可以与任何T2V扩散模型配合使用,无需额外训练。 自动错位识别:自动检测文本和视频之间的细粒度错位。 空间和文本反馈:生成明确的空间和文本反馈,指导视频的局部精细化。
方法概述
VideoRepair 包括四个主要阶段:
1、视频评估阶段:
生成评估问题:通过生成细粒度的评估问题来检测不对齐问题。 使用MLLM回答问题:利用大规模语言模型(MLLM)回答这些问题,以识别视频中的不对齐区域。
2、细化规划阶段:
识别准确生成的对象:确定哪些对象已经正确生成。 创建局部提示:为未正确生成的区域创建局部提示,以便进行精细化调整。
3、区域分解阶段:
分割正确生成的区域:使用组合的定位模块将视频分割成正确生成的区域和需要调整的区域。
4、局部细化阶段:
调整不对齐的区域:通过调整不对齐的区域同时保留正确区域,重新生成视频。
实验结果
研究人员在两个流行的视频生成基准测试(EvalCrafter和T2V-CompBench)上评估了VideoRepair的性能。结果显示,VideoRepair在各种文本-视频对齐度量上显著优于最近的基线方法。
EvalCrafter:VideoRepair在文本-视频对齐度量上显著优于其他方法,特别是在处理复杂场景时。 T2V-CompBench:VideoRepair在多个指标上表现出色,包括对象识别、属性对齐和整体视频质量。
组件分析和定性示例
研究人员提供了对VideoRepair各组件的全面分析,详细说明了每个阶段的作用和效果。此外,他们还展示了多个定性示例,展示了VideoRepair在实际应用中的效果。
视频评估阶段:生成的评估问题能够准确检测视频中的不对齐区域,MLLM的回答提供了可靠的反馈。 细化规划阶段:局部提示的创建使得模型能够针对性地调整不对齐的区域,而不影响正确生成的部分。 区域分解阶段:分割算法能够准确区分正确生成的区域和需要调整的区域,确保局部细化的精确性。 局部细化阶段:重新生成的视频在保持正确区域的同时,显著改善了不对齐区域的质量,使得最终视频与文本提示高度对齐。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...