Snap和罗格斯大学的研究人员推出新型单步视频生成模型SF-V,此模型的核心特点是能够通过一次前向传播(single forward pass)快速生成高质量、运动连贯的视频,这对于需要实时视频合成和编辑的应用场景非常有用。例如,你想要创造一个视频,里面展示一只猫在追逐自己的尾巴。传统的方法可能需要你逐帧地调整猫的动作,这不仅耗时而且技术要求高。而"SF-V"模型通过一次操作就能生成整个视频,大大简化了视频制作的过程。
通过对抗性训练,多步视频扩散模型,即稳定视频扩散(Stable Video Diffusion, SVD),可以被训练以执行单次前向传递来合成高质量视频,同时捕捉视频数据中的时间和空间依赖关系。广泛实验表明,SF-V在显著降低去噪过程的计算开销的同时(即,与SVD相比约快23倍,与现有工作相比快6倍,且生成质量更佳),达到了合成视频的竞争性生成质量,为实时视频合成与编辑铺平了道路。不过,SF-V模型还存在一些限制,比如在单步生成设置下,视频的编码和解码部分仍然占据了相当一部分的运行时间,作者将这些模型的加速作为未来的工作方向。

主要功能和特点:
- 单步生成:模型能够在一次计算过程中生成完整的视频,相比需要多次迭代的模型,这大大加快了视频生成速度。
- 高质量视频:生成的视频不仅清晰度高,而且具有自然和连贯的运动。
- 时间空间连贯性:视频中的对象运动符合物理规律和时间连续性,使得视频看起来更真实。
- 计算效率高:相比于传统的扩散模型,"SF-V"在生成视频时的计算成本大幅降低。
工作原理:
- "SF-V"模型基于扩散模型,这类模型通常通过逐步去除噪声来生成数据。然而,传统扩散模型需要多次迭代来逐步改善视频帧,这既耗时又计算密集。
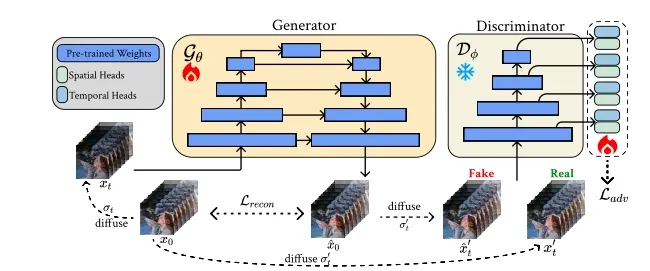
- 为了解决这个问题,"SF-V"采用了对抗训练(adversarial training)来微调预训练的视频扩散模型,使其能够在单步生成中达到与多步生成相似或更好的质量。
- 模型利用了一个生成器和一个鉴别器。生成器负责从噪声中生成视频帧,而鉴别器则评估生成的视频帧并提供反馈,以此来训练生成器改进其输出。
具体应用场景:
- 娱乐行业:可以快速生成电影或游戏的动画场景。
- 社交媒体:用户可以迅速创作并分享具有个性化动作的视频内容。
- 数字内容创作:设计师和艺术家可以利用这个模型来创造动态视觉艺术作品。
- 实时视频编辑:在直播或实时视频制作中,可以即时生成或修改视频内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...