
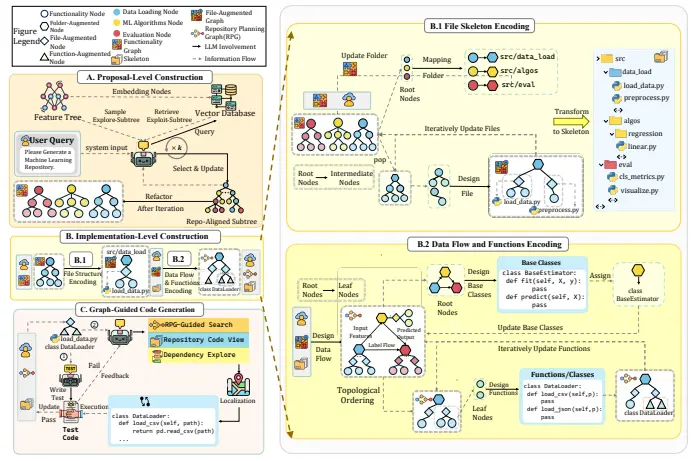
来自北京大学和快手科技的研究人员推出新型文本到视频生成框架VideoTetris,此框架专门设计来解决现有方法在处理复杂场景(如多对象或对象数量动态变化的长视频)生成时面临的挑战。VideoTetris通过空间和时间上的组合式扩散模型,能够精确地遵循复杂的文本语义,生成符合描述的视频内容。例如,你想要创造一个视频,描述了一个英勇的机器人和一个拥有魔法的女孩在拯救世界。传统的方法可能会在生成这样的场景时遇到困难,因为它们需要同时处理多个对象以及它们之间的空间和时间关系。VideoTetris框架通过理解和组合文本中的各个元素,能够生成这样的复杂视频场景。
VideoTetris支持组合式的T2V(文本到视频)生成。具体而言,开发人员提出了时空组合扩散方法,通过空间和时间上操纵及组合去噪网络的注意力图,来精确遵循复杂的文本语义。此外,开发人员还提出了一种增强的视频数据预处理方法,旨在针对运动动态和提示理解改进训练数据,并配备了一种新的“参考帧注意力”机制,以提高自回归视频生成的一致性。广泛的实验表明,VideoTetris在组合式T2V生成中取得了令人印象深刻的定性和定量结果,彰显了在处理复杂视频内容生成任务中的优越性能。

不过,VideoTetris还存在一些限制,例如在长视频生成中的性能限制,以及计算成本和过渡帧数量的挑战。未来的工作将探索更通用的长视频生成方法,并在更强大的预训练模型和更大的高质量视频数据集上扩展这一新的视频扩散范式。同时,作者强调了这项技术的双重用途性质,提醒社会对其可能的滥用风险保持警惕。

主要功能和特点:
- 空间-时间组合式扩散:通过操作去噪网络的注意力图,VideoTetris能够在视频中自然地集成和融合不同的对象。
- 增强的视频数据预处理:通过增强运动动态和提示理解,提升长视频生成模型处理复杂语义的能力。
- 参考帧注意力机制:通过保持内容一致性,确保视频中多个对象在不同帧和位置上的一致性。
- 无需训练的应用:VideoTetris可以直接应用于现有的文本到视频模型,如VideoCrafter2和AnimateDiff,而无需额外的训练。
工作原理:
- VideoTetris首先将文本提示分解为不同的时间帧和空间对象。
- 然后,它计算每个子对象的交叉注意力值,并在空间和时间上进行组合,以形成自然的视频故事。
- 为了增强长视频的生成能力,VideoTetris采用了一种增强的视频数据预处理流程,通过选择具有一致运动动态的视频片段,并重新描述视频以确保与复杂的文本提示相匹配。
- 通过引入参考帧注意力模块,VideoTetris能够在生成过程中保持对象特征的一致性。
具体应用场景:
- 创意内容制作:VideoTetris可以用于生成符合特定故事情节的视频,适用于电影、游戏和动画制作。
- 社交媒体:用户可以利用这个框架生成描述特定场景或事件的视频,用于社交媒体分享。
- 广告行业:通过生成吸引人的视频广告,VideoTetris可以帮助企业更有效地传达产品信息。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











