
腾讯优图实验室和南京大学的研究人员推出新技术RealTalk,它是一个用于生成逼真、实时的音频驱动人脸视频的框架。简单来说,RealTalk可以根据一个人的语音生成一个看起来非常真实的3D人脸动画,而且这个人脸的动作能够和语音同步,就像真的在说话一样。例如,你有一段录音,RealTalk可以根据这个录音创造出一个虚拟的发言人。这个虚拟人物不仅看起来像真的,而且它的嘴唇动作会和录音完全同步,甚至能够展现出说话时的微妙表情变化。
RealTalk该框架由两部分构成:音频至表情转换器与高保真表情至面部渲染引擎。首先,在音频至表情转换环节,研究团队综合分析了与言语中唇动相关的个人身份特性和个体内部变化特征,并通过在富含面部先验知识的基础上引入跨模态注意力机制,确保唇动与音频信号的紧密匹配,极大提升了表情预测的准确度。其次,研究团队构建了一个轻量级的面部身份对齐(FIA)模块,该模块独创性地融合了唇形操控架构与面部纹理参照系统。这一设计使得系统能够高效产出细腻的面部效果,无需依赖复杂低效的特征匹配流程,实现了实时性能。实验结果显示,无论从量化评估还是质性分析角度看,RealTalk在唇语同步精确度及画面生成质量上,对比现有方法均展现出显著优势。更重要的是,此框架兼具高效与低资源消耗特性,完美契合实际应用场景的需求。
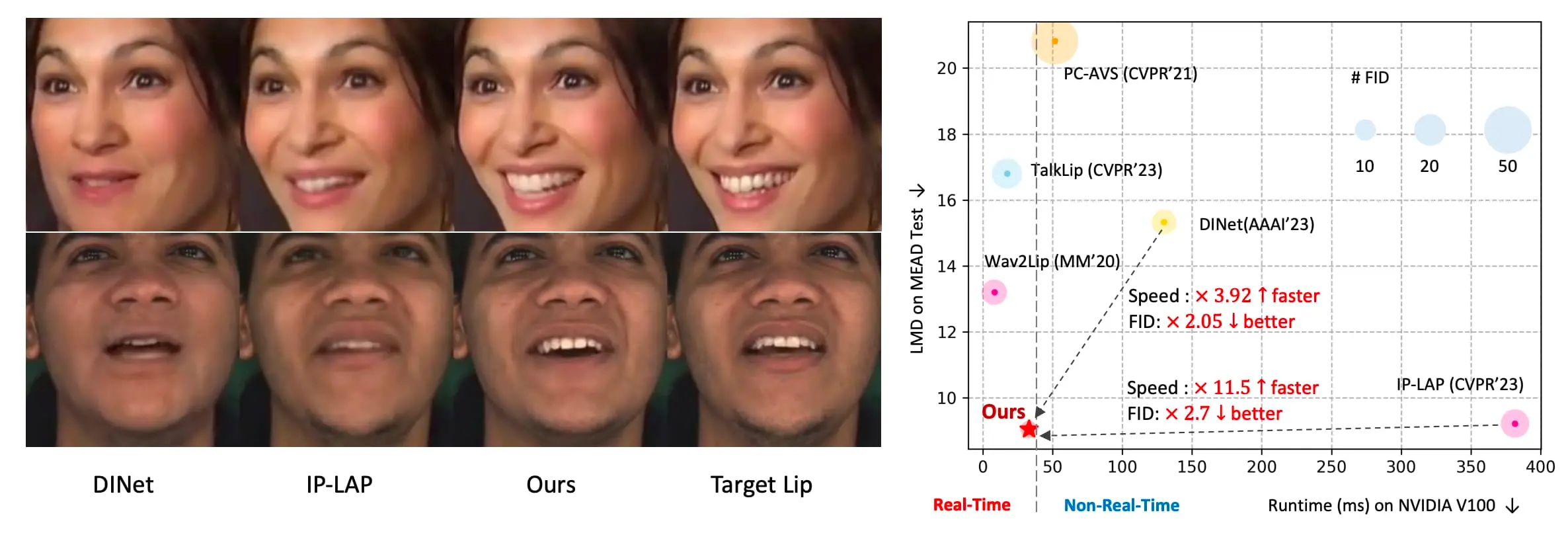
主要功能:
- 将音频输入转换为3D表情系数。
- 生成与音频同步的高保真度人脸动画。
- 实时生成高质量的人脸渲染效果。
主要特点:
- 实时性能:RealTalk能够以每秒30帧的速度生成人脸视频,适合实时应用。
- 高保真度:通过精心设计的表情到面部渲染器(expression-to-face renderer),RealTalk能够生成细节丰富的高质量人脸图像。
- 3D面部先验:利用3D面部模型来引导表情预测,提高唇部同步的精度。
- 身份保持:即使在生成新的表情时,也能够保持与原始人物相似的面部特征。
工作原理:
- 音频到表情的转换器:首先,RealTalk使用一个音频到表情的转换器(audio-to-expression transformer),它通过跨模态注意力机制(cross-modal attention)考虑个体身份和内部变化特征,如表情和姿势,从而将输入的音频特征与3D面部先验对齐,预测出精确的表情系数。
- 表情到面部的渲染器:然后,这些预测的表情系数被输入到一个高保真度的表情到面部渲染器中,该渲染器包含一个轻量级的身份对齐模块(Facial Identity Alignment, FIA),用于生成具有精细细节的实时人脸图像。
具体应用场景:
- 虚拟主播:在新闻、体育赛事或天气预报中,RealTalk可以用来生成虚拟的主播或发言人。
- 电影和游戏:在电影制作或电子游戏中,RealTalk可以用来创建逼真的角色对话和表情动画。
- 虚拟现实:在虚拟现实环境中,RealTalk可以生成与用户互动的虚拟角色,提供更加自然和真实的交流体验。
- 远程交流:在视频会议或远程教学中,RealTalk可以用来增强参与者的表达能力,即使在网络条件不佳的情况下也能保持交流的流畅性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











