
来自亚利桑那州立大学、英特尔实验室、Hugging Face和华盛顿大学的研究人员推出SPRIGHT T2I,探讨如何改进文生图(Text-to-Image,简称T2I)模型在生成图像时保持空间一致性的能力。简单来说,就是让计算机根据我们用文字描述的场景,生成的图片能够准确地反映出文字中提到的物体之间的位置关系。
这项研究通过创建新的数据集和改进训练方法,显著提升了计算机根据文本描述生成图像的能力,特别是在理解和表达物体间空间关系方面。这不仅推动了人工智能在视觉领域的研究,也为多种实际应用场景提供了强有力的技术支持。
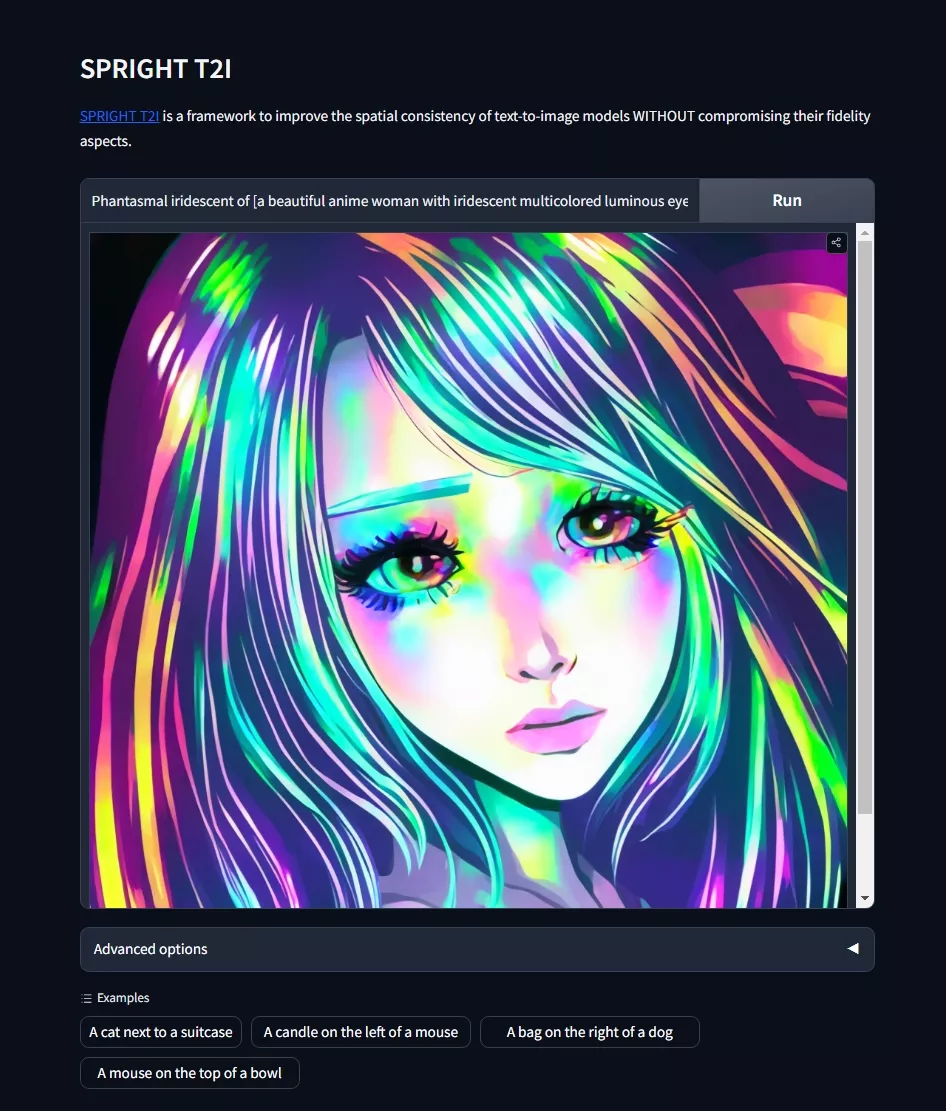
主要功能和特点:
- 创建了SPRIGHT数据集: 这是一个大规模的数据集,专注于图像中的空间关系。研究者们通过重新为600万张图片配文,创建了这个数据集,这些配文更加注重描述图像中的物体是如何相对排列的。
- 提高了空间关系的捕捉能力: 通过对比现有的视觉-语言数据集,SPRIGHT数据集在捕捉图像中的空间关系方面有了显著提升。
- 改进了T2I模型的训练方法: 论文中提出了一种高效的训练方法,通过在包含大量物体的图像上进行训练,显著提高了模型在空间一致性方面的表现。
工作原理:
- 数据集的构建: 研究者们首先发现现有的数据集在表示空间关系方面做得不够好。为了解决这个问题,他们使用了大型语言模型LLaVA来生成新的配文,这些配文详细描述了图像中的物体位置和大小关系。
- 模型训练: 接着,他们使用了这个新创建的SPRIGHT数据集来训练文本到图像的扩散模型(如Stable Diffusion模型)。通过特别关注空间关系的描述,模型学会了更好地理解和生成符合文本描述的图像。
具体应用场景:
- 视频生成和编辑: 改进后的T2I模型可以用于生成高质量的视频内容,例如根据剧本自动生成电影场景的图像序列。
- 机器人技术: 在机器人视觉系统中,准确的空间关系理解可以帮助机器人更好地导航和理解周围环境。
- 图像编辑软件: 这项技术可以集成到图像编辑软件中,让用户通过简单的文字描述就能创造出复杂的图像场景,无需复杂的图形设计技能。
- 游戏开发: 游戏设计师可以利用这种技术根据描述快速生成游戏场景的概念图,加速游戏开发过程。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











