
阿里巴巴和蚂蚁集团推出新型文生图框架Ranni,Ranni的核心特点是它能够更准确地理解和执行复杂的文本提示,尤其是那些包含数量描述、对象属性绑定和多主题描述的提示。这使得Ranni在生成图像时能够更加精确地遵循用户的详细指示。
现有的文生图模型在解析复杂提示时通常面临挑战,特别是当提示涉及数量、对象属性绑定和多主体描述时。在这项工作中,开发团队引入了一个语义面板作为将文本解码为图像的中间环节,以辅助生成器更好地遵循指令。这个面板是通过利用大语言模型解析输入文本中的视觉概念,并将它们有序排列而得到的。随后,开发团队将这个面板作为详细的控制信号注入到去噪网络中,以补充文本条件。为了简化文本到面板的学习过程,开发团队设计了一套语义格式化协议,并配备了一套全自动的数据准备流程。得益于这样的设计,开发团队提出的Ranni能够增强预训练的文生图模型在文本控制方面的能力。更重要的是,引入生成性中间件提供了一种更便捷的交互方式(即用户可以直接调整面板中的元素或使用语言指令),进一步允许用户进行精细的自定义生成。基于这一理念,开发团队开发了一个实用的系统,并展示了它在连续生成和基于聊天的编辑方面的巨大潜力。

例如,如果用户想要生成一幅画,描述为“一只穿着红色帽子的熊猫在草地上踢足球”,Ranni能够理解这个描述,并生成一个包含所有这些元素的图像。如果用户想要对图像进行编辑,比如“把熊猫变成老虎”,Ranni也能够根据这个指令更新语义面板,并重新生成图像。这种交互式和连续的编辑过程使得Ranni成为一个强大且灵活的图像生成工具。
主要功能:
Ranni的主要功能是将自然语言描述转换成高质量的图像。它通过引入一个语义面板(semantic panel)作为中间件,帮助生成器更好地遵循指令。这个面板通过大型语言模型(Large Language Models, LLMs)解析输入文本中的视觉概念,并将其注入到去噪网络中,作为详细的控制信号,以补充文本条件。
主要特点:
- 语义面板: Ranni使用语义面板作为文本和图像之间的桥梁,提供了对文本描述的准确理解,并允许直观的图像编辑。
- 交互式编辑: 用户可以直接调整语义面板中的元素或使用语言指令进行微调,从而实现对生成图像的精细定制。
- 连续生成: Ranni支持连续生成,允许用户通过多轮编辑逐步完善图像。
工作原理: Ranni的工作流程分为两个主要部分:文本到面板(Text-to-Panel)和面板到图像(Panel-to-Image)。
- 文本到面板: 利用大型语言模型解析文本提示,将其转换成视觉概念,并在语义面板中进行排列。
- 面板到图像: 将语义面板编码为控制信号,引导去噪模型捕捉每个概念的细节,从而生成图像。
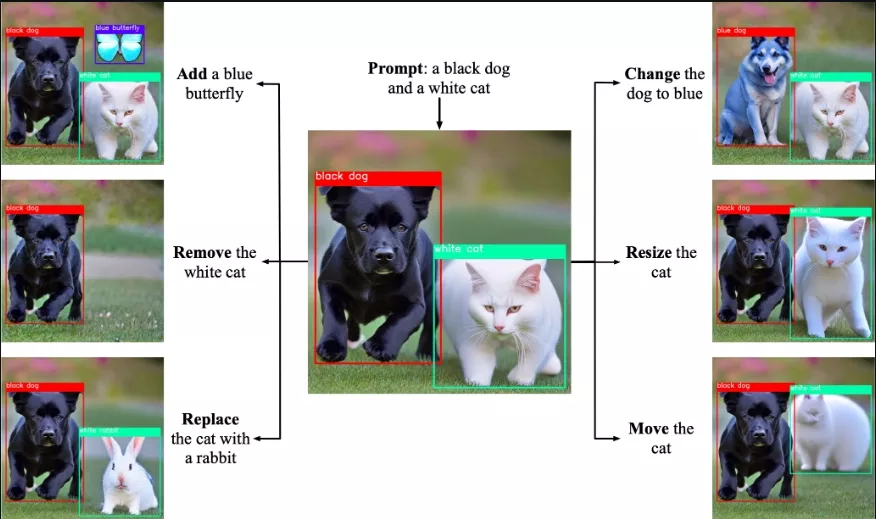
具体应用场景: Ranni的应用场景非常广泛,包括但不限于:
- 艺术创作: 艺术家和设计师可以使用Ranni来实现他们的创意,通过文本描述生成精确的图像。
- 游戏和娱乐: 在游戏设计和电影制作中,Ranni可以用来快速生成场景和角色的概念艺术。
- 教育和培训: Ranni可以用于创建教学材料,帮助学生更好地理解复杂的概念。
- 社交媒体内容创作: 用户可以在社交媒体上使用Ranni来创建个性化的图像和插图,增强他们的帖子和故事。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











