来自字节跳动和罗格斯大学的研究人员推出新型图像生成模型MoMA(Multimodal LLM Adapter),这是一个开放词汇、无需训练的个性化图像模型,具有灵活的零样本能力,专注于主体驱动的个性化图像生成。开发团队利用开源的多模态大语言模型(MLLM)来训练MoMA,使其能够同时担任特征提取器和生成器的双重角色。这种方法有效地结合了参考图像和文本提示信息,生成有价值的图像特征,从而助力图像扩散模型。
- 项目主页:https://moma-adapter.github.io
- 论文地址:https://arxiv.org/abs/2404.05674
- GitHub:https://github.com/bytedance/MoMA
- 模型地址:https://huggingface.co/KunpengSong/MoMA_llava_7b
为了更好地利用这些生成的特征,开发团队进一步引入了一种新颖的自注意力捷径方法,该方法能够高效地将图像特征传递给图像扩散模型,进而提升生成图像中目标对象的相似度。值得一提的是,MoMA作为一个免调优的即插即用模块,仅需一张参考图像,便能在生成高细节保真度、增强身份保持性和文本提示忠实性的图像方面超越现有方法。

MoMA能够根据用户的文本提示和一张参考图片快速生成个性化的图像。例如,你给MoMA一张猫的照片和一段描述,比如“一只猫在秋天的落叶中”,它就能生成一系列新的图片,展示这只猫在不同秋天背景下的样子,或者改变猫的纹理,如将其变成一只青铜雕塑的猫。
主要功能和特点:
- 开放词汇表和无需训练: MoMA不需要针对每个新主题进行训练,可以直接使用。
- 零样本能力: 即使之前没有见过某个主题,MoMA也能根据文本描述生成图像。
- 高细节保真度: MoMA生成的图像在细节上与参考图像非常相似,能够保持主题的身份特征。
- 与文本提示的一致性: MoMA能够理解文本提示的内容,并在生成的图像中体现出来。
工作原理:
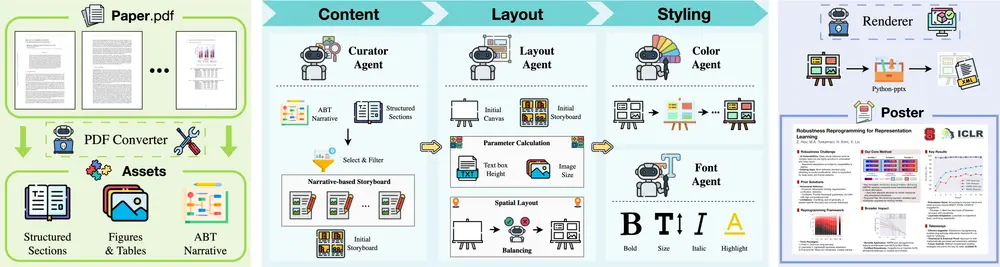
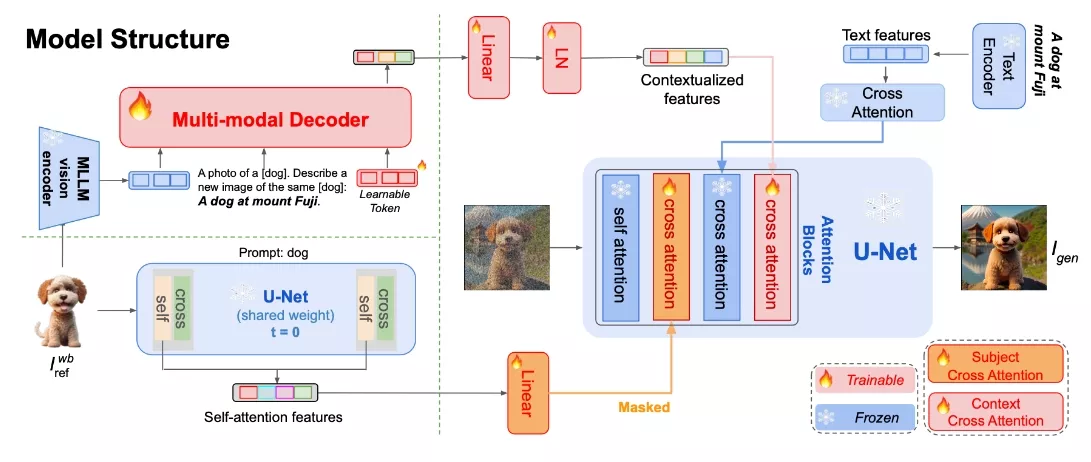
- 多模态特征提取: MoMA使用一个预训练的多模态大型语言模型(MLLM)来提取参考图像的特征,并结合文本提示生成图像特征。
- 自注意力快捷方式: 为了提高目标对象在生成图像中的相似度,MoMA引入了一种新的自注意力快捷方法,有效地将图像特征传递给图像扩散模型。
- 两阶段训练: 首先,MoMA通过多模态生成学习阶段预训练,学习如何结合视觉特征和文本提示;其次,在扩散学习阶段,它固定MLLM和预训练的扩散模型,只优化新添加的注意力模块。
具体应用场景:
- 个性化内容创作: MoMA可以用于生成个性化的社交媒体内容,如根据用户上传的照片和描述创建独特的图像。
- 游戏和虚拟现实: 在游戏或VR应用中,MoMA可以根据玩家的选择实时生成或修改游戏中的角色和环境。
- 艺术创作辅助: 艺术家可以使用MoMA来快速尝试不同的创作概念,如改变画作中的主题纹理或背景。
- 广告和营销: MoMA可以帮助设计师根据特定的营销主题快速生成一系列广告图像,提高工作效率。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











