
清华和智谱 AI的研究团队开源了图像生成模型 CogView3 以及CogView-3-Plus ,CogView3 是一个基于级联扩散的文本生成图像系统,采用了接力扩散(relay diffusion)框架,来生成高质量的图像。 CogView-3Plus 是一系列新开发的基 Diffusion Transformer 的文本生成图像模型。
- GitHub:https://github.com/THUDM/CogView3
- 模型:https://github.com/THUDM/CogView3/blob/main/sat/README_zh.md
- Plus模型:HuggingFace/ModelScope
CogView3
CogView3是第一个在文生图领域实现接力扩散的模型,通过首先创建低分辨率图像,然后应用基于接力的超分辨率来执行任务。这种方法不仅产生了具有竞争力的文本到图像输出,而且大大降低了训练和推理成本。实验结果表明,CogView3在人类评估中优于当前最先进的开源文本到图像扩散模型SDXL,提高了77.0%,同时仅需要大约1/2的推理时间。CogView3的蒸馏变体在仅使用SDXL推理时间的1/10的情况下实现了可比性能。
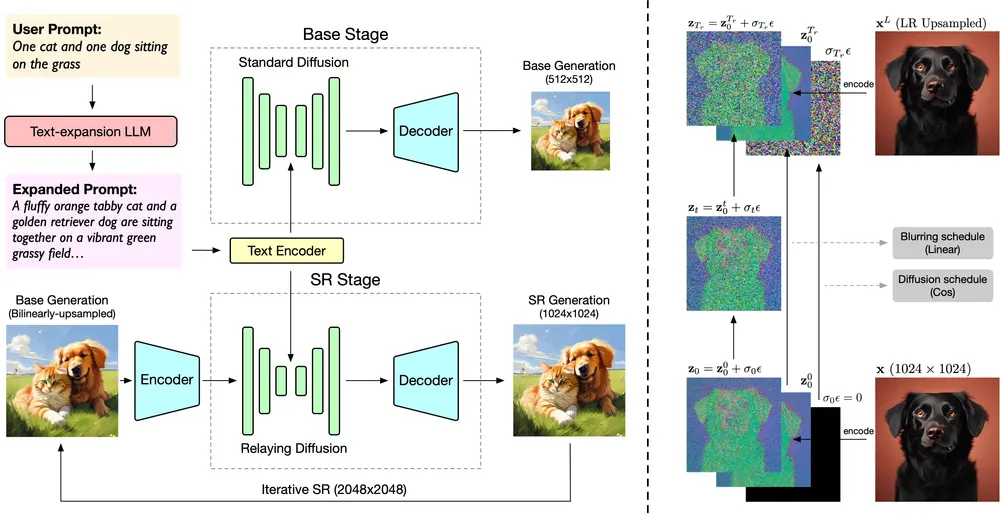
CogView3 是一个基于级联扩散的 text2img 模型,其包含如下三个阶段:
第一阶段:利用标准扩散过程生成 512x512 低分辨率的图像。
第二阶段:利用中继扩散过程,执行 2 倍的超分辨率生成,从 512x512 输入生成 1024x1024 的图像。
第三阶段:将生成结果再次基于中继扩散迭代,生成 2048×2048 高分辨率的图像。

CogView-3-Plus
CogView-3-Plus 在 CogView3的基础上引入了最新的 DiT 框架,以实现整体性能的进一步提升。CogView-3-Plus 采用了 Zero-SNR 扩散噪声调度,并引入了文本-图像联合注意力机制。与常用的 MMDiT 结构相比,它在保持模型基本能力的同时,有效降低了训练和推理成本。CogView-3Plus 使用潜在维度为 16 的 VAE。

CogView3主要特点
- 接力扩散:CogView3采用了一种新的接力扩散框架,首先生成低分辨率的图像,然后通过接力超分辨率生成高分辨率的图像。
- 高效率:与现有的文本到图像扩散模型相比,CogView3在训练和推理时需要的计算资源更少。
- 高质量输出:CogView3在生成图像的细节和复杂性方面表现出色,能够生成非常细致的图像。
CogView3工作原理
- 文本预处理:用户输入的文本描述首先被处理以增强模型的理解。
- 基础模型:CogView3的基础阶段模型生成一个低分辨率的图像。
- 接力超分辨率:然后,通过在低分辨率图像上添加高斯噪声并从这些噪声图像开始扩散过程,生成高分辨率的图像。
- 迭代实现:通过迭代实现超分辨率阶段,CogView3能够生成极高分辨率(如2048×2048)的图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











