
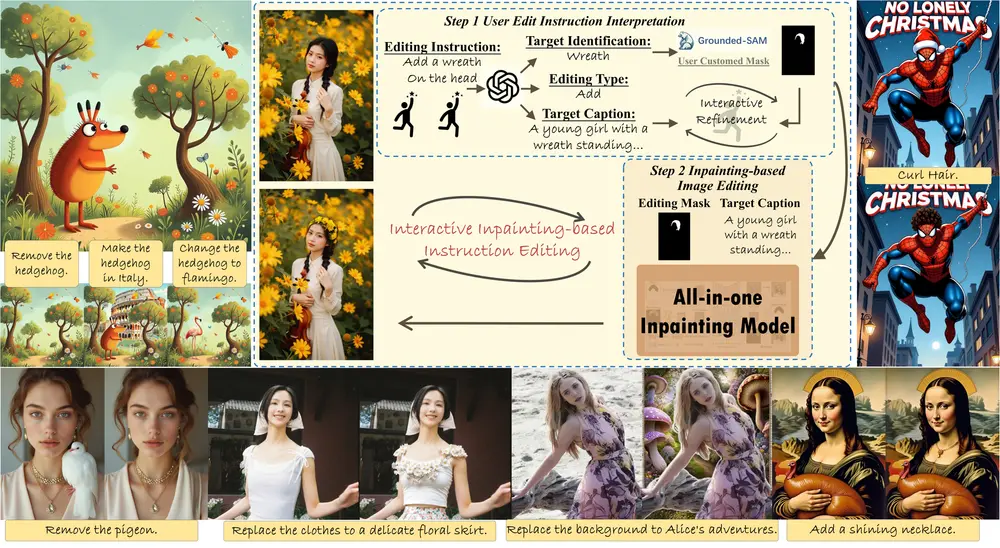
小红书推出图像生成模型StoryMaker,它专门设计用于在文本到图像的生成过程中保持人物的一致性。这种一致性不仅限于人物的面部特征,还包括服装、发型和身体特征。通过这种方式,StoryMaker能够根据文本提示生成一系列具有连贯故事性的图像。(参考:漫画生成框架StoryDiffusion)
StoryMaker是一种个性化的解决方案,不仅能保持面部一致性,还能保持服装、发型和身体的一致性,从而通过一系列图像促进故事的创作。StoryMaker 结合了基于面部身份和裁剪后的角色图像的条件,其中包含了服装、发型和身体的信息。具体来说,研究团队使用位置感知感知器重采样器(PPR)将面部身份信息与裁剪后的角色图像结合,以获取独特的人物特征。为了避免多个角色与背景之间的混淆,研究团队分别使用均方误差损失(MSE loss)和分割掩模约束不同角色和背景之间的交叉注意力影响区域。此外,我们通过姿态条件训练生成网络,以促进姿态解耦。此外,还使用了 LoRA来提升保真度和质量。

例如,你是一名漫画家,想要创造一个关于“上班族一天的生活”的故事,你可以使用StoryMaker根据这个主题生成一系列图像,其中的人物在不同的场景中保持一致的外观和服装。或者,如果你是一名服装设计师,想要展示你的设计在不同人物上的效果,StoryMaker可以帮助你生成具有相同服装但不同人物特征的图像系列。

主要功能和特点:
- 全面一致性: StoryMaker不仅能够保持人物的面部一致性,还能够保持服装、发型和身体特征的一致性。
- 条件生成: 通过文本提示,用户可以生成具有特定背景、姿势和风格的图像系列,从而构建故事。
- 个性化定制: 支持根据特定的参考图像生成具有一致性的新图像,例如在不同场景下保持相同的人物外观。
- 与现有技术的兼容性: 可以与其他社会插件(如LoRA用于风格化)兼容,增强图像的多样性和质量。
工作原理:
StoryMaker的工作原理包括以下几个关键步骤:
- 提取参考信息: 使用面部编码器(如Arcface)和图像编码器(如CLIP视觉编码器)从参考图像中提取人物的面部特征和身体特征。
- 信息细化: 通过位置感知感知器重采样器(Positional-aware Perceiver Resampler, PPR)整合面部身份信息和裁剪的人物图像,以获得独特的人物特征。
- 解耦姿势: 通过ControlNet在训练时对姿势进行控制,以促进生成图像的姿势多样性。
- 质量增强: 使用LoRA(Low-Rank Adaptation)层来提高图像的保真度和质量。
- 注意力区域约束: 使用均方误差(MSE)损失和分割掩码来约束不同人物和背景的交叉注意力影响区域,防止它们相互干扰。
具体应用场景:
- 数字故事讲述: 利用一系列文本提示生成连贯的人物图像,用于故事可视化和漫画创作。
- 个性化图像生成: 根据用户提供的参考图像生成具有一致性的新图像,适用于个性化定制和社交媒体内容创作。
- 服装交换和风格化: 通过替换人物图像中的服装部分或应用不同的风格化插件,实现服装交换和风格化图像生成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











