
来自北京大学、InsightFace和格灵深瞳推出IDAdapter,它能够根据单张面部照片和文本提示,生成多种风格、角度和表情的个性化图像,而无需在推理阶段进行任何微调。
IDAdapter通过结合文本和视觉信息的注入以及面部身份损失,将个性化概念整合到生成过程中。这种方法在训练阶段使用多个参考图像的混合特征来丰富与身份相关的细节,指导模型生成风格、表情和角度更多样化的图像。

例如,如果你有一张自己的照片,并想要生成一张穿着中世纪骑士盔甲、在夕阳下、在雨中、带有皮克斯动画风格、表情惊讶的图像,IDAdapter可以根据这些文本提示生成满足要求的图像,同时保证面部特征与原照片高度一致。
主要功能和特点:
- 无需微调:IDAdapter不需要在推理时对模型进行微调,可以直接使用预训练的扩散模型。
- 高保真度:生成的图像保持了与原始面部照片的高相似度,同时展现出丰富的风格和表情。
- 多样化输出:能够根据文本提示生成多样化的图像,包括不同的风格、角度和表情。
工作原理:
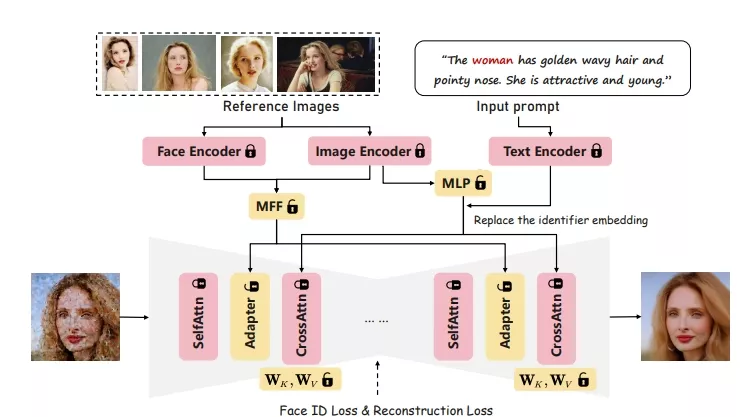
IDAdapter通过冻结基础扩散模型的主要权重,在单个GPU上训练不到10小时。在推理阶段,只需要一张参考图像和文本提示,就能生成多样化、高保真度的图像。它通过混合特征模块(MFF)从多个参考图像中提取面部特征,并通过适配器层将这些特征注入到模型中,从而生成个性化的图像。
具体应用场景:
- 个性化头像生成:用户可以根据自己的照片和喜好,生成具有个性化特征的卡通或艺术风格的头像。
- 社交媒体内容创作:社交媒体用户可以使用IDAdapter根据自己的情绪或场景需求,快速生成个性化的图片内容。
- 游戏角色定制:游戏开发者可以利用IDAdapter为玩家提供定制化的角色创建工具,让玩家基于自己的面部特征创建游戏角色。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











