现有的多视图图像生成方法通常对预训练的文生图模型进行侵入性修改,并需要全面微调,导致高计算成本和图像质量下降。为了解决这些问题,北京航空航天大学、VAST 和上海交通大学的研究人员提出了 MV-Adapter,这是一个基于适配器的多视图图像生成解决方案。
- 项目主页:https://huanngzh.github.io/MV-Adapter-Page
- GitHub:https://github.com/huanngzh/MV-Adapter
- Demo:https://huggingface.co/spaces/VAST-AI/MV-Adapter-I2MV-SDXL
- ComfyUI插件:https://github.com/huanngzh/ComfyUI-MVAdapter
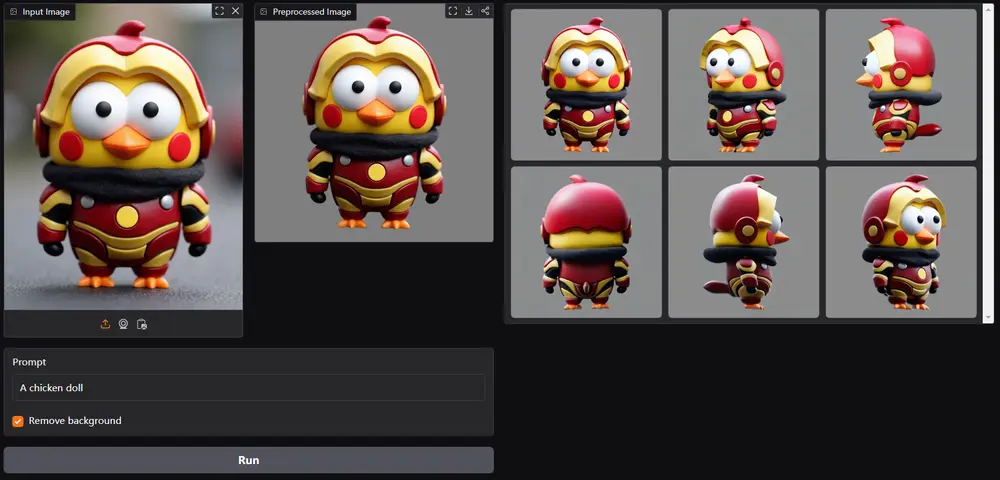
MV-Adapter 是一个多功能即插即用适配器,能够在不改变原始网络结构或特征空间的情况下增强文生图模型及其衍生模型,目前主要是基于SDXL模型。通过更新较少的参数,MV-Adapter 实现了高效的训练,并保留了预训练模型中嵌入的先验知识,降低了过拟合风险。
模型
| 模型 | 基础模型 | 模型地址 | Demo地址 |
|---|---|---|---|
| Text-to-Multiview | SDXL | mvadapter_t2mv_sdxl.safetensors | General / Anime |
| Image-to-Multiview | SDXL | mvadapter_i2mv_sdxl.safetensors | Demo |
| Text-Geometry-to-Multiview | SDXL | ||
| Image-Geometry-to-Multiview | SDXL | ||
| Image-to-Arbitrary-Views | SDXL |
核心技术创新
1. 即插即用适配器设计
MV-Adapter 的核心是一个即插即用适配器,它可以无缝集成到现有的文生图模型中,而无需对原始模型进行任何侵入性修改。这意味着用户可以轻松地将 MV-Adapter 应用于各种文生图模型及其衍生模型,包括:
- 个性化模型:如 DreamShaper
- 蒸馏模型:如 LCM(Latent Consistency Model)
- 扩展模型:如 ControlNet
这种灵活性使得 MV-Adapter 可以在不同的应用场景中快速部署,适应多种生成任务。
2. 创新的 3D 几何建模
为了有效建模 3D 几何知识,研究人员引入了以下创新设计:
- 重复的自注意力层:通过在适配器中引入重复的自注意力层,MV-Adapter 能够更好地捕捉多视图之间的空间关系,确保生成的图像在不同视角下保持一致。
- 平行注意力架构:平行注意力架构允许适配器同时处理来自不同视角的输入,增强了模型的多视图生成能力。这种设计使得 MV-Adapter 能够继承预训练模型的强大先验知识,从而更好地建模新的 3D 知识。
3. 统一的条件编码器
MV-Adapter 还引入了一个 统一的条件编码器,能够无缝集成相机参数和几何信息。这个条件编码器使得模型可以在基于文本和图像的条件下生成高质量的多视图图像,并支持几何引导的纹理生成。通过这种方式,MV-Adapter 不仅能够生成多视图一致的图像,还能在生成过程中融入更多的 3D 信息,提升生成效果的真实感和一致性。
性能优势
1. 高效训练与低计算成本
由于 MV-Adapter 只更新少量参数,训练过程更加高效,显著降低了计算成本。这对于大型基础模型和高分辨率图像尤为重要,避免了传统方法中全面微调带来的高昂计算开销。
2. 高质量多视图生成
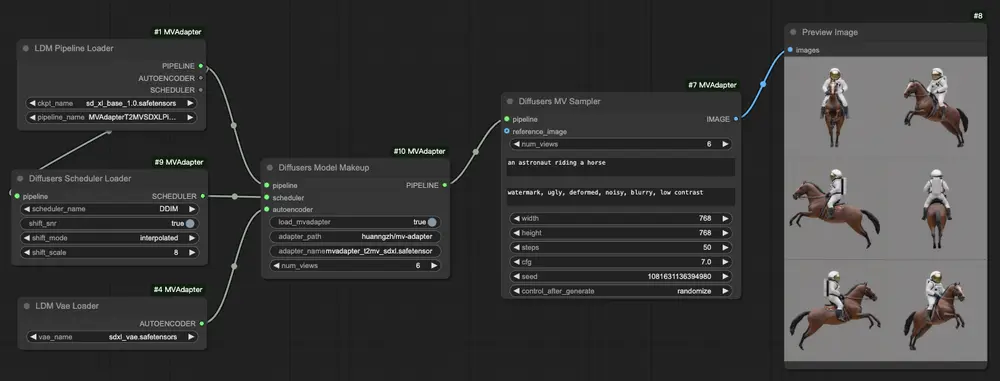
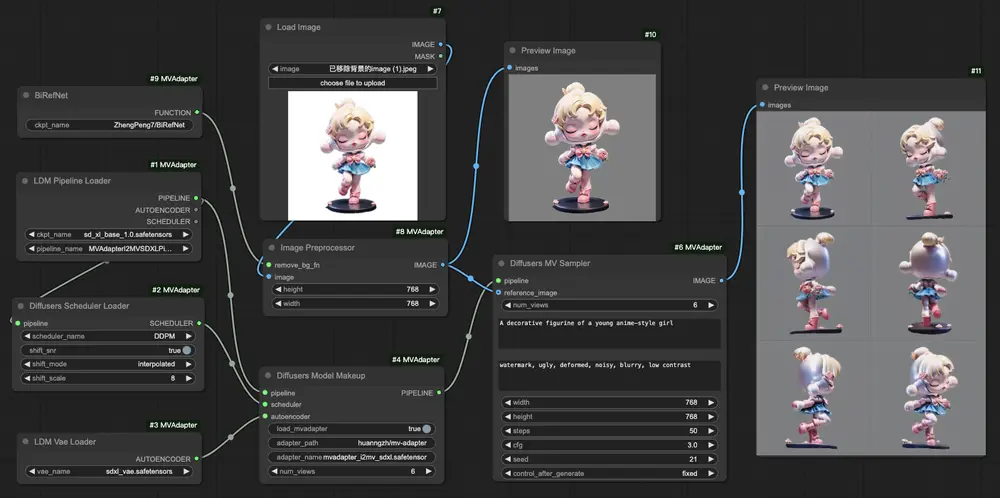
尽管训练参数较少,MV-Adapter 仍然能够生成高质量的多视图图像。实验结果显示,MV-Adapter 在 Stable Diffusion XL(SDXL)上实现了 768 分辨率的多视图生成,并展示了出色的适应性和多功能性。生成的图像在不同视角下保持高度一致,且细节丰富,真实感强。
3. 广泛的适用性
MV-Adapter 不仅适用于标准的 T2I 模型,还可以扩展到任意视图生成,支持更广泛的应用场景。例如,用户可以根据需要生成多个视角的图像,或者在生成过程中加入几何引导,实现更复杂的 3D 效果。
实验验证
研究人员对 MV-Adapter 进行了广泛的实验验证,结果表明,MV-Adapter 在多个基准测试中均表现出色,特别是在生成高质量多视图图像方面。此外,用户研究显示,参与者普遍认为 MV-Adapter 生成的图像在不同视角下保持了高度的一致性和真实感,提升了整体的观看体验。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
![黑森林实验室联合 KREA AI 发布 FLUX.1 Krea [dev]: 实现更真实、更自然的图像生成](https://pic.sd114.wiki/wp-content/uploads/2025/08/1753986665-1753986665-FLUX-Krea-2.webp~tplv-o4t1hxlaqv-image.image)



暂无评论...











