加州大学洛杉矶分校、松下AI研究院和Salesforce AI研究院的研究人员共同提出了OmniFlow,这是一种新颖的生成模型,专为处理“任何到任何”(any-to-any)生成任务设计,如文本到图像、文本到音频和音频到图像合成。OmniFlow通过扩展校正流(Reversible Flow, RF)框架以处理多模态联合分布,显著提升了在多种生成任务中的表现。例如,你想要生成一张“夜晚东京繁忙的市中心街道,有霓虹招牌、人行道和高楼大厦”的图片,或者将一段描述海浪拍打岸边的文本转换成实际的海浪声音,OmniFlow都能够实现这些跨模态的转换。
- GitHub:https://github.com/jacklishufan/OmniFlows
- 模型:https://huggingface.co/jacklishufan/OmniFlow-v0.5
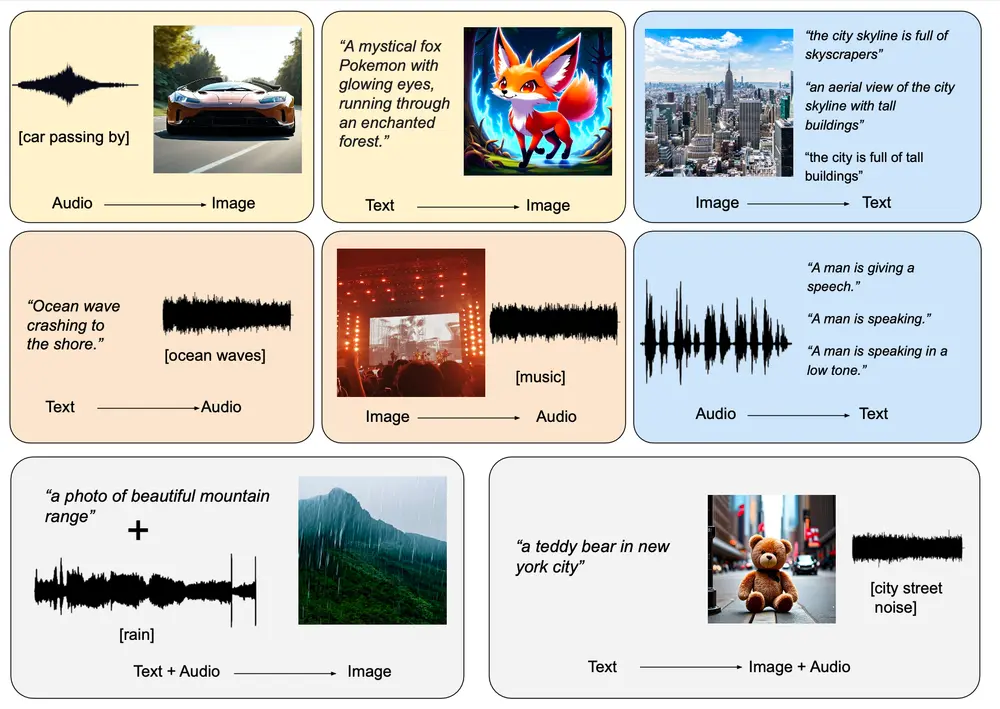
主要功能:
- 多模态生成:能够处理包括文本、图像和音频在内的多种模态之间的转换。
- 灵活控制:通过多模态引导机制,用户可以灵活控制生成输出中不同模态之间的对齐。
- 高性能:在多个基准测试中,OmniFlow显示出比现有模型更好的性能。
主要特点:
- 模块化设计:OmniFlow采用了模块化架构,允许各个组件独立预训练,然后合并进行微调,节省了大量的计算资源。
- 多模态引导:引入了多模态引导机制,使得模型在生成过程中能够更好地对齐不同模态。
- 统一框架:在一个统一的框架内支持灵活的任何到任何生成任务。
关键贡献
OmniFlow的工作提供了三个主要的技术贡献,这些贡献共同推动了多模态生成模型的发展:
1、RF框架的多模态扩展与灵活引导机制
- 多模态校正流:研究人员将原本用于文本到图像生成的校正流(RF)框架扩展到了多模态设置中。这一扩展使得OmniFlow能够处理不同模态之间的复杂关系,并生成高质量的跨模态内容。
- 灵活的引导机制:为了增强用户对生成输出的控制,OmniFlow引入了一种新颖的引导机制。这种机制允许用户灵活地调整生成输出中不同模态之间的对齐,从而实现更加个性化和精确的生成结果。
2、创新的架构设计
- 扩展Stable Diffusion 3的MMDiT架构:OmniFlow基于Stable Diffusion 3的文本到图像MMDiT架构进行了扩展,增加了对音频和文本生成的支持。扩展模块可以单独高效地预训练,并在微调阶段与原始的文本到图像MMDiT合并,确保了模型的灵活性和高效性。
- 模块化设计:这种模块化的设计不仅简化了模型的训练过程,还使得OmniFlow能够轻松适应新的模态和任务,进一步增强了其应用范围。
3、全面的研究与优化
- 校正流变换器的设计选择:研究人员对大规模音频和文本生成中校正流变换器的设计选择进行了全面研究,探讨了不同的配置和参数设置对性能的影响。这项研究为优化跨多样模态的性能提供了宝贵的见解,帮助未来的研究者更好地设计和改进多模态生成模型。
工作原理:
OmniFlow基于矩形流(RF)框架,通过时间可微的插值(time-differentiable interpolation)在多模态数据对的分布和独立高斯噪声之间建立联系。它使用路径(path)在噪声水平之间表示不同的生成任务,并通过最小化流匹配目标(flow matching objective)来训练模型。此外,OmniFlow还引入了多模态引导,允许模型在生成过程中更灵活地控制不同模态之间的交互。
性能评估
实验结果显示,OmniFlow在广泛的任何到任何生成任务中表现出色,包括但不限于:
- 文本到图像生成:生成的图像质量高,细节丰富,且与输入文本高度相关。
- 文本到音频合成:生成的音频自然流畅,语音清晰,音质优良。
- 音频到图像合成:根据音频内容生成相应的图像,具有较高的视觉一致性和创意性。
应用前景
OmniFlow的提出不仅为多模态生成任务提供了一个强大的工具,还为未来的研究和发展奠定了坚实的基础。随着技术的不断进步,我们期待看到更多基于OmniFlow的创新应用,如:
- 虚拟助手:结合文本、音频和图像生成能力,提供更加智能和个性化的交互体验。
- 内容创作:帮助创作者快速生成高质量的内容,涵盖从插图到配乐的各个方面。
- 教育和培训:通过生成多样化的学习材料,提升教学效果和学生的学习兴趣。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











