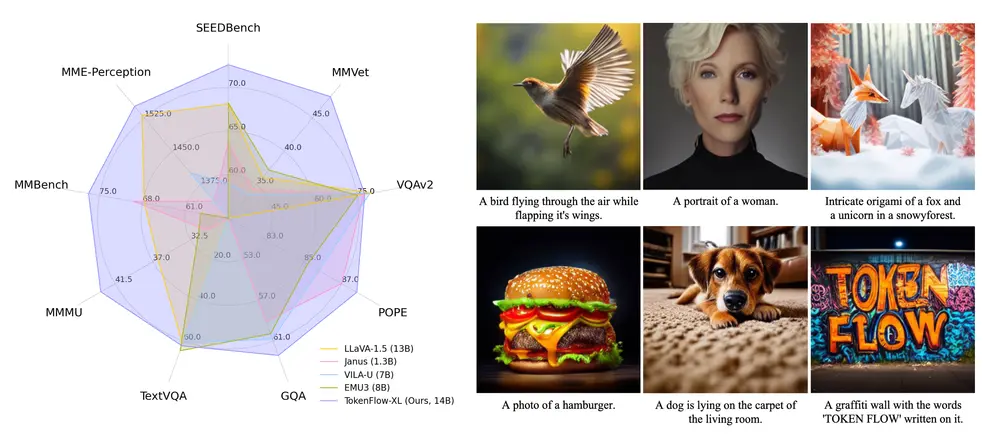
萨里大学和NetMind.AI的研究人员提出了NitroFusion,这是一种根本不同的单步扩散方法,旨在通过动态对抗框架实现高质量的图像生成。尽管单步方法在速度上具有显著优势,但它们通常在生成质量上不如多步方法。NitroFusion通过引入一系列创新机制,成功克服了这一挑战,实现了高保真单步生成。
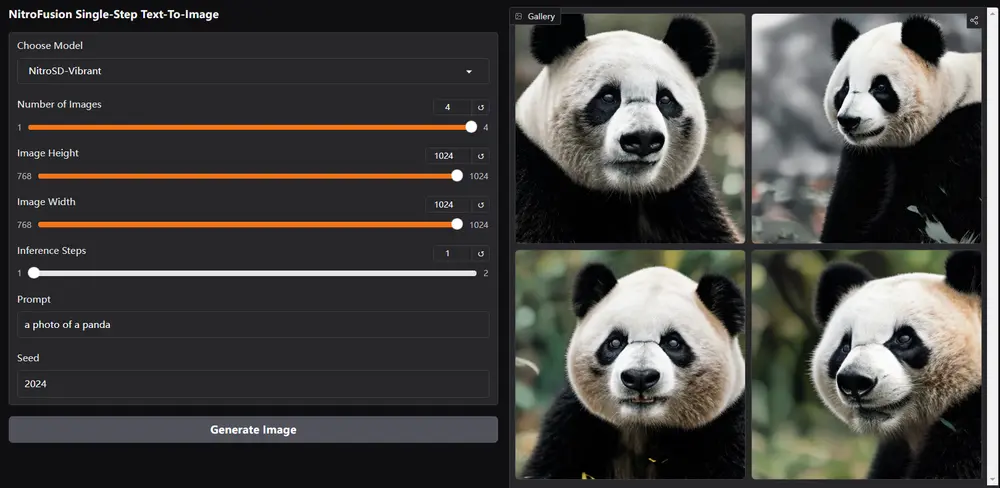
- 项目主页:https://chendaryen.github.io/NitroFusion.github.io
- 模型:https://huggingface.co/ChenDY/NitroFusion
- Demo:https://huggingface.co/spaces/ChenDY/NitroFusion_1step_T2I
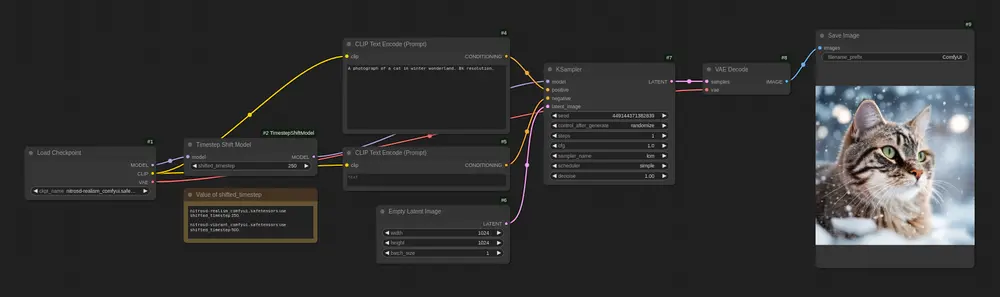
- ComfyUI插件:https://github.com/ChenDarYen/ComfyUI-TimestepShiftModel
例如,你想要生成一张描绘“一位穿着西装的山羊坐在海边悬崖上”的图片。使用NitroFusion,你只需提供一个文本提示,模型就能在单次推理步骤中生成一张细节丰富、逼真的图像,而不需要传统的多步骤生成过程。

主要功能
NitroFusion的主要功能包括:
- 单步生成:能够在单一推理步骤中生成高质量图像,显著加快生成速度。
- 动态对抗性训练:通过动态更新的对抗性判别器池来提高生成质量。
- 多尺度质量评估:结合全局和局部判别器头,实现多尺度质量评估。
- 无条件/条件训练:平衡生成图像的一致性和对文本提示的响应。
主要特点
- 动态判别器池:维护一个大型的、动态变化的判别器头池,为生成过程提供多样化的反馈。
- 策略性刷新机制:定期重新初始化一部分判别器头,防止过拟合并保持反馈多样性。
- 全局-局部判别器头:评估图像的整体一致性和局部细节,提升生成质量。
- 灵活部署:支持1-4步去噪步骤的灵活选择,允许用户根据需要在速度和质量之间进行权衡。
工作原理
NitroFusion的工作原理涉及以下几个关键步骤:
- 动态判别器池:利用一个大型判别器头池,每个头专注于不同的噪声水平和质量方面,提供多样化的反馈。
- 对抗性训练:通过对抗性损失来训练生成器,使生成的图像能够欺骗判别器,从而提高图像质量。
- 多尺度策略:使用全局和局部判别器头来评估图像的不同尺度,确保图像在宏观和微观层面上的质量。
- 无条件/条件训练:通过无条件和条件判别器头的双重训练目标,平衡图像的自然性和对文本提示的适应性。
具体应用场景
NitroFusion的应用场景包括:
- 实时互动系统:在需要快速生成高质量图像的应用中,如虚拟现实(VR)和增强现实(AR)。
- 内容创作:为艺术家和设计师提供一个工具,以便快速实现创意视觉概念的可视化。
- 社交媒体:用户可以快速生成与特定文本描述相匹配的图像,用于社交媒体分享。
- 广告和营销:快速生成吸引人的广告图像,以提高用户参与度和品牌吸引力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











