
Jasper推出了一种高效、快速、多用途且与LoRA兼容,旨在加速预训练扩散模型生成的蒸馏方法Flash Diffusion,该方法在COCO 2014和COCO 2017数据集上,针对少量步骤的图像生成,在FID分数和CLIP-Score指标上达到了先进水平的表现,同时仅需数小时的GPU训练时间以及比现有方法更少的可训练参数。除了效率之外,该方法的多用途性也在多个任务中得到展示,包括文本到图像转换、图像修复、换脸、超分辨率处理,以及使用不同扩散模型骨干网络的应用,无论是基于UNet的去噪器(如SD1.5、SDXL)还是DiT(如Pixart-α),以及各类适配器。在所有情况下,该方法都能显著减少采样步骤的数量,同时保持极高的图像生成质量。总之,Flash Diffusion 是一个能够显著提高图像生成速度的技术,同时保持了图像的高质量,这使得它在需要快速生成图像的各种应用中都非常有用。
- 项目主页:https://gojasper.github.io/flash-diffusion-project
- GitHub:https://github.com/gojasper/flash-diffusion
- 模型地址:https://huggingface.co/collections/jasperai/flash-diffusion-665dd5e62d8dafd54d5afd33
- Demo:https://huggingface.co/spaces/jasperai/flash-diffusion
例如,你有一个魔法画笔,开始时它只是一团混乱的颜色(相当于高斯噪声),但随着你不断使用这个画笔,它逐渐展现出清晰的图像。这个过程就像是扩散模型的工作方式,它们通过逐步去除噪声来生成图像。但是,这个过程很慢,需要很多次的尝试和错误。而“Flash Diffusion”就是让这个过程变得非常快速,几乎瞬间就能得到你想要的图像。
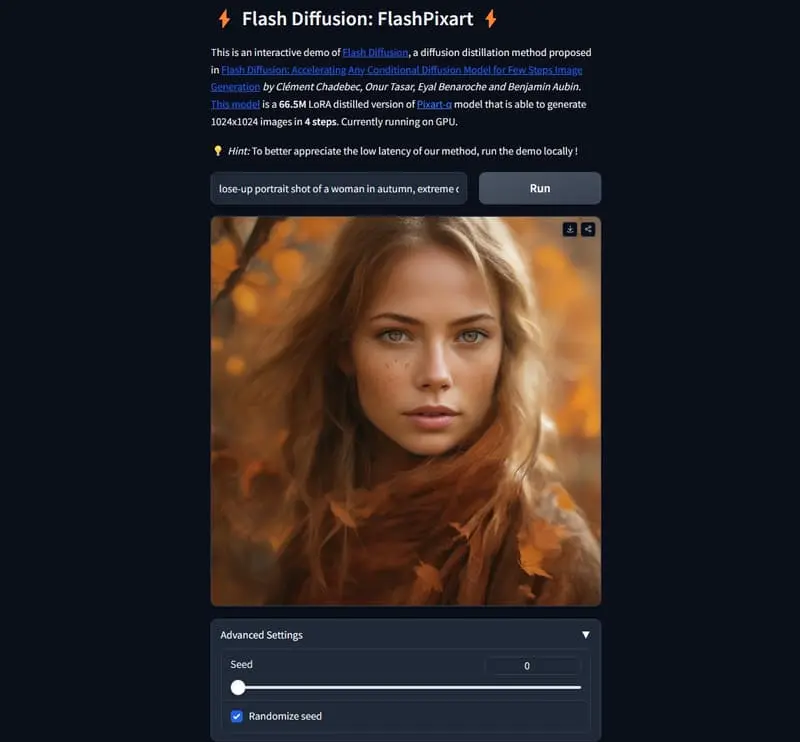
主要功能:
- 加速图像生成过程,减少生成高质量图像所需的迭代步骤。

主要特点:
- 快速:通过特殊的训练方法,Flash Diffusion 能够在短时间内生成图像。
- 高效:相比于原始的扩散模型,Flash Diffusion 需要的训练资源更少。
- 多用途:适用于多种图像生成任务,如文本到图像的转换、图像修复、超分辨率等。
工作原理:
- 学生模型:训练一个学生模型来预测在几步迭代后,教师模型(一个已经训练好的扩散模型)将如何去除噪声。
- 对抗性目标:使用对抗性训练,使得学生模型生成的图像难以与真实数据分布区分开来。
- 分布匹配:确保学生模型生成的样本与教师模型学习到的数据分布保持一致。
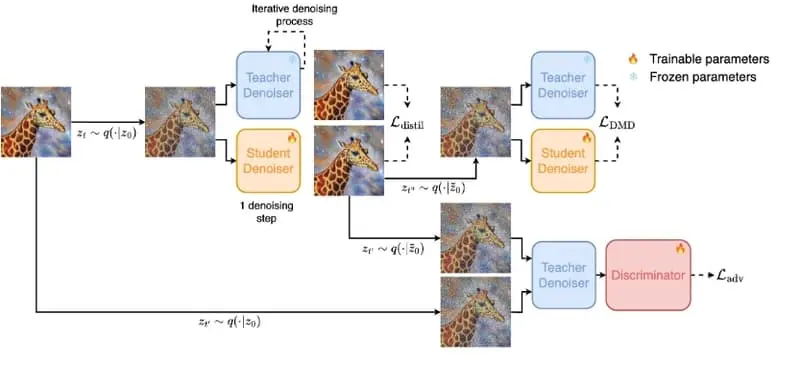
具体应用场景:
- 文本到图像:根据文本描述快速生成图像。
- 图像修复:快速填充图像中的缺失或损坏部分。
- 超分辨率:提高图像分辨率,同时保持图像质量。
- 面部交换:在图像或视频中快速替换人物的面部。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











