
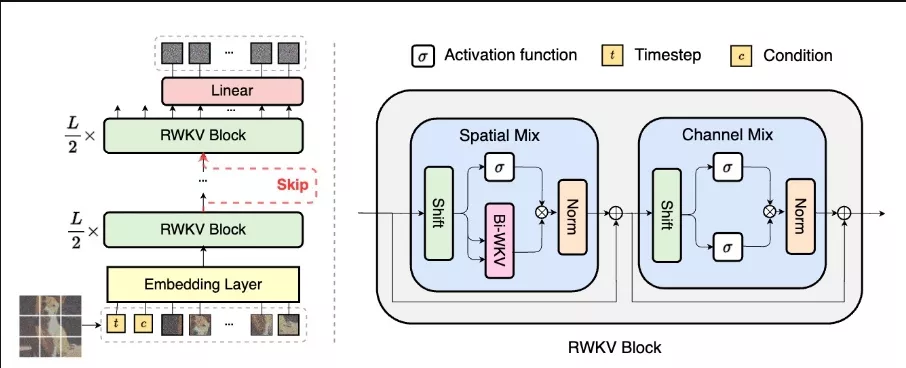
昆仑万维推出新型文生图架构Diffusion-RWKV,它是为了改进图像生成任务而设计的。这个架构是基于RWKV模型,这是一种在自然语言处理(NLP)领域中使用的模型,但经过了特别的修改,使其更适合处理图像生成任务。
与基于Transformer的扩散模型相似,Diffusion-RWKV旨在高效地处理带有额外条件的序列中的分片输入,同时实现有效的扩展,以适应大规模参数和广泛的数据集。其独特之处在于降低了空间聚合复杂性,使其在处理高分辨率图像时尤为出色,从而避免了窗口化或分组缓存操作的必要。实验结果表明,在条件和无条件图像生成任务上,Diffusion-RWKV在FID和IS指标上的性能与现有基于CNN或Transformer的扩散模型相当或更优,同时显著减少了总计算FLOPs的使用量。

主要功能和特点:
- 高效处理高分辨率图像: Diffusion-RWKV模型特别擅长处理高分辨率的图像,因为它减少了空间聚合的复杂性,这意味着它能够更有效地处理图像的细节。
- 降低计算复杂度: 与传统的Transformer模型相比,Diffusion-RWKV模型在处理长序列任务时具有更低的计算复杂度,这使得它在资源有限的情况下也能表现良好。
- 可扩展性: 该模型能够适应大规模的参数和大型数据集,这使得它在处理大量数据时仍然能够保持高效的性能。
- 与现有模型相比较: 在实验中,Diffusion-RWKV在图像生成质量上与现有的CNN或Transformer基础的扩散模型相当,同时显著降低了总计算FLOP(浮点运算)的使用。
工作原理:
Diffusion-RWKV模型的工作原理基于扩散模型的概念,这是一种通过迭代地将随机噪声转化为可识别数据的生成模型。这个过程包括一个正向的噪声添加过程和一个反向的去噪过程。在正向过程中,模型逐步向数据中添加高斯噪声,创建一个潜在变量的马尔可夫链。在反向过程中,一个去噪网络被训练来学习如何根据噪声输入去除添加的噪声。在推理阶段,可以从随机高斯噪声中采样数据点,并通过学习到的去噪过程逐步去噪样本,生成最终的数据。
具体应用场景:
- 高分辨率图像生成: 由于其高效处理高分辨率图像的能力,Diffusion-RWKV模型可以用于生成高清晰度的艺术作品或照片。
- 图像合成: 在电影和游戏产业中,这个模型可以用来合成逼真的背景或角色图像。
- 数据增强: 在机器学习的训练过程中,Diffusion-RWKV可以用来生成额外的训练样本,提高模型的泛化能力。
- 图像修复和恢复: 该模型还可以应用于图像修复任务,例如修复损坏的照片或恢复历史画作的原始面貌。
总的来说,Diffusion-RWKV模型是一种强大的工具,它通过结合RWKV模型的优势和对图像生成任务的特别优化,提供了一种高效、可扩展的解决方案,适用于多种图像处理和生成的场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











