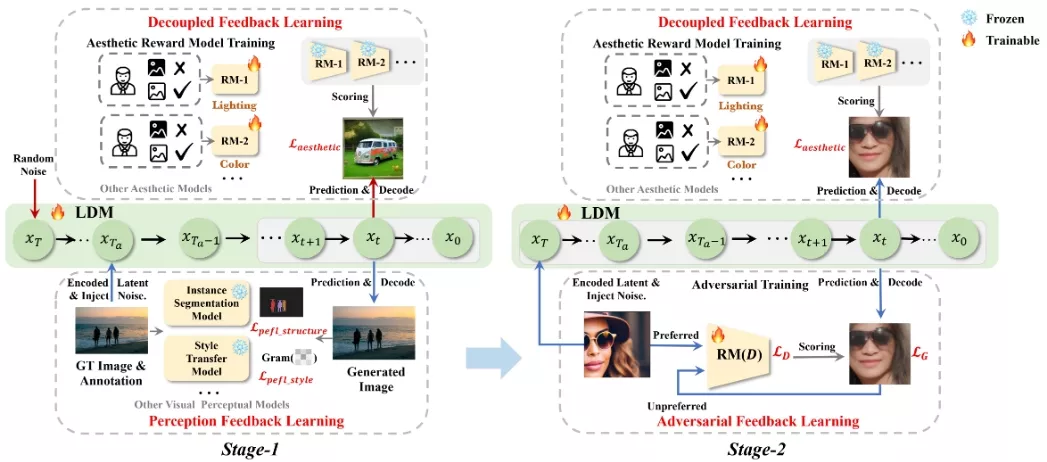
来自字节跳动和中山大学的研究人员推出利用反馈学习机制来全面增强扩散模型的统一框架UniFL,它通过统一的反馈学习来提升稳定扩散模型(Stable Diffusion)的性能。UniFL作为一种通用、高效且易于泛化的解决方案,适用于各种扩散模型,如SD1.5和SDXL。UniFL融合了三个核心组件:感知反馈学习,旨在提升生成图像的视觉质量;解耦反馈学习,用于增强图像的审美吸引力;以及对抗反馈学习,致力于优化模型的推理速度。
通过深入的实验和广泛的用户研究,开发团队验证了UniFL在提升生成模型质量和加速推理方面的卓越性能。例如,在生成质量方面,UniFL以17%的用户偏好率超越了ImageReward;在四步推理方面,UniFL的性能分别比LCM和SDXL Turbo高出57%和20%。此外,还验证了UniFL在下游任务中的有效性,包括Lora、ControlNet和AnimateDiff等应用。

主要功能和特点:
- 提升视觉质量: UniFL通过感知反馈学习(Perceptual Feedback Learning, PeFL)来增强图像的视觉质量,例如通过改进图像的风格和结构。
- 增强审美吸引力: 通过解耦反馈学习(Decoupled Feedback Learning),UniFL能够针对颜色、布局、细节和光照等不同维度来优化图像的美学质量。
- 加速推理过程: 利用对抗性反馈学习(Adversarial Feedback Learning),UniFL优化了模型的推理速度,使得在较少的推理步骤下仍能生成高质量的图像。
工作原理: UniFL框架包含三个关键组件:
- 感知反馈学习(PeFL): 利用现有的感知模型(如VGG网络和实例分割模型)来提供关于图像特定方面的反馈,如风格和结构,从而指导扩散模型进行改进。
- 解耦反馈学习: 将美学概念分解为多个维度,并分别对它们进行注释和优化,以便更有效地进行审美反馈学习。
- 对抗性反馈学习: 通过对抗性训练,将奖励模型和扩散模型一起训练,使得在低去噪步骤下生成的样本也能通过奖励反馈得到良好的优化,从而实现快速推理。
具体应用场景:
- 艺术创作: UniFL可以帮助艺术家和设计师生成高质量的图像,用于创作或作为灵感来源。
- 个性化内容生成: 用户可以根据个人喜好生成定制图像,例如个性化的设计图案或特定风格的艺术作品。
- 娱乐和游戏开发: 在游戏和娱乐产业中,UniFL可以用来快速生成大量符合特定审美标准的图像,用于游戏场景或虚拟环境的构建。
- 教育和培训: UniFL可以用于制作教育材料,如将复杂的概念转化为易于理解的视觉图像。
总的来说,UniFL是一个强大的工具,它通过结合多种反馈学习技术,显著提高了稳定扩散模型在图像生成方面的性能,特别是在质量和速度方面,使其更适合于广泛的实际应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











