
新加坡国立大学的研究团队推出 MakeAnything,这是一个基于DiT模型的多领域程序化序列生成框架,能够根据文本描述或图像生成分步骤的教程,也就是生成一致性图片序列。
- GitHub:https://github.com/showlab/MakeAnything
- 模型:https://huggingface.co/showlab/makeanything
- Demo:MakeAnything|MakeAnything-AsymmertricLoRA
该框架旨在解决生成复杂多步骤程序化序列的三个关键挑战:多任务程序化数据的稀缺性、步骤之间的逻辑连贯性和视觉一致性,以及跨多个领域的泛化能力。MakeAnything 通过引入一个涵盖 21 个任务、超过 24,000 个程序化序列的多领域数据集,并结合新颖的技术设计,实现了高质量的程序化序列生成。

例如,用户可以输入“如何用金色画笔画一个女孩的肖像?”或上传一幅画作的图片,MakeAnything 能够生成详细的分步骤绘画教程,包括从草图到最终成品的每一步操作。
主要功能
- 文本到程序化序列生成:根据文本描述生成分步骤的教程,涵盖绘画、手工制作、烹饪等多种领域。
- 图像到程序化序列生成:通过上传静态图片,反向生成该图片的创作过程。
- 跨领域泛化:支持多种领域(如绘画、手工、烹饪等)的程序化序列生成,具有良好的泛化能力。
- 可控生成:通过条件输入(如文本或图像)控制生成过程,确保生成结果与输入条件高度一致。
主要特点
- 多领域数据集:提出了一个涵盖 21 个任务、超过 24,000 个程序化序列的多领域数据集,显著推动了程序化理解与生成的研究。
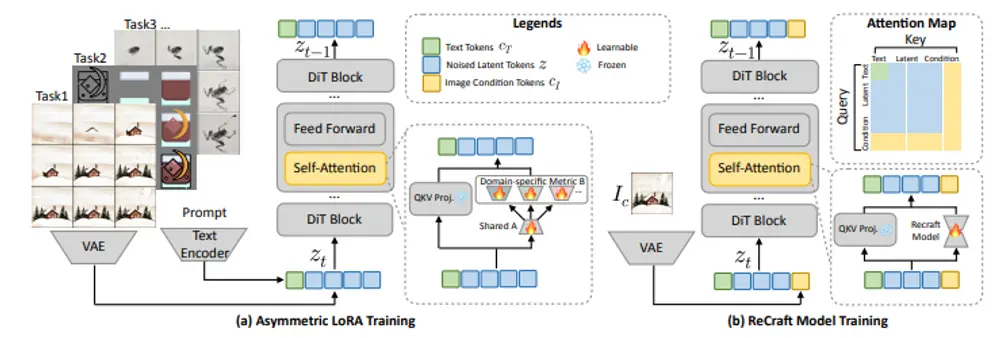
- 不对称低秩适配(Asymmetric LoRA):通过冻结编码器参数并自适应调整解码器层,平衡了泛化能力和任务特定性能。
- ReCraft 模型:通过时空一致性约束,将静态图像分解为合理的创作序列,支持图像条件的程序化生成。
- 高质量生成:结合高质量数据集和先进的技术设计,生成的程序化序列在逻辑连贯性和视觉一致性方面表现出色。
工作原理
- 扩散变换器(DiT):作为基础模型,DiT 通过逐步去噪生成高质量的图像序列。它处理两种类型的 token:噪声图像 token 和文本条件 token,通过多模态注意力机制实现双向注意力。
- 不对称 LoRA:通过联合训练共享的中心矩阵和多个任务特定矩阵,平衡了泛化能力和任务特定性能。这种方法在多任务学习中表现出色。
- ReCraft 模型:通过将目标图像的干净潜在 token 注入去噪过程中,指导中间帧的去噪,从而实现从静态图像生成合理的创作序列。
- 条件流匹配损失:通过最小化模型生成的条件向量场与真实数据分布之间的差异,优化生成过程。
具体应用场景
- 教育与培训:为学生提供绘画、手工制作、烹饪等领域的分步骤教程,帮助他们更好地理解和学习创作过程。
- 创意设计:为设计师提供灵感,生成从概念到成品的创作步骤,支持绘画、图标设计、3D 建模等多种创意领域。
- 反向工程:通过上传成品图片,反向生成创作过程,帮助用户理解和重建复杂的创作步骤。
- 在线教程生成:为在线教育平台自动生成高质量的教程内容,提升用户体验。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











