
近年来,交互式分割模型(如 SAM)在图像分割任务中取得了显著进展。然而,这些模型在应用于交互式抠图任务时面临挑战,尤其是在处理复杂和遮挡场景时。现有的方法通常在合成数据上训练模型,但这些模型难以泛化到真实的复杂场景中。华东理工大学、vivo 和新加坡管理大学的研究人员提出了一种新的方法——SEMat,通过构建一个新的抠图数据集 COCO-Matting 和改进的网络架构及训练目标,解决了上述问题。
COCO-Matting 数据集
数据集构建:
- 附件融合:从 COCO 数据集中选择现实世界的复杂图像,并将语义分割掩码转换为抠图标签。
- 掩码到抠图:将语义分割掩码转换为抠图标签,生成 alpha 抠图。
- 数据规模:COCO-Matting 包含 38,251 个人类实例级别的 alpha 抠图,涵盖了复杂自然场景中的广泛数据。
数据集特点:
- 多样性:涵盖各种复杂自然场景,包括遮挡、光照变化和纹理复杂的情况。
- 高质量:每个实例级别的 alpha 抠图都经过仔细标注,确保高质量的数据。

SEMat 方法
网络架构:
- 特征对齐变换器(Feature-Aligned Transformer):学习提取细粒度的边缘和透明度特征,这对于抠图任务至关重要。
- 抠图对齐解码器(Matte-Aligned Decoder):旨在分割特定于抠图的对象,并将粗略掩码转换为高精度抠图。
训练目标:
- 正则化损失:保留预训练模型的先验知识,防止模型过度拟合。
- trimap 损失:推动从掩码解码器提取的抠图 logits 包含基于 trimap 的语义信息,提高抠图的准确性。
主要功能和特点
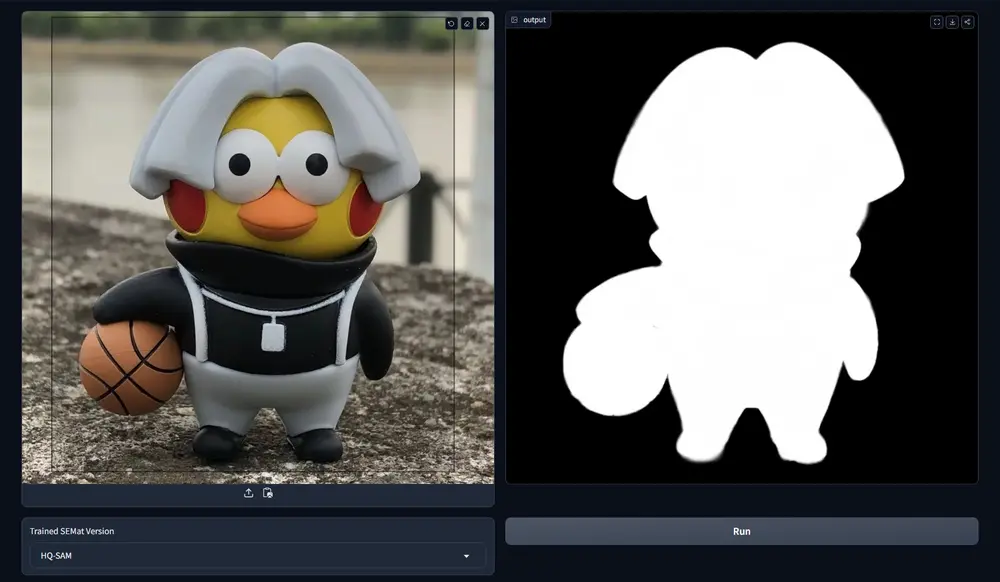
- 精确的边缘和透明度特征提取:SEMat 通过特征对齐变换器提取图像中精细的边缘和透明度特征,这对于抠图任务至关重要。
- 针对性的对象分割:SEMat 的抠图对齐解码器能够识别和分割出特定于抠图的对象,如烟雾、网状物和丝绸等,这些在传统的图像分割任务中不常见。
- 无需微调:SEMat 在测试时不需要复杂的微调,这意味着用户可以更快速、更便捷地生成定制视频。

工作原理
- 特征对齐变换器(Feature-Aligned Transformer):利用额外的提示(如边界框提示)来引导视觉变换器(如 ViT)关注目标对象,从而提取与抠图任务更对齐的特征。
- 抠图对齐解码器(Matte-Aligned Decoder):通过添加特殊的抠图标记和适配器来增强 SAM(Segment Anything Model)的掩码解码器,使其能够更准确地分割出抠图特定的对象。
- 训练目标:引入正则化损失和 trimap 损失,以保留预训练模型的先验知识,并推动从掩码解码器提取的抠图逻辑包含 trimap 基于的语义信息。
实验结果
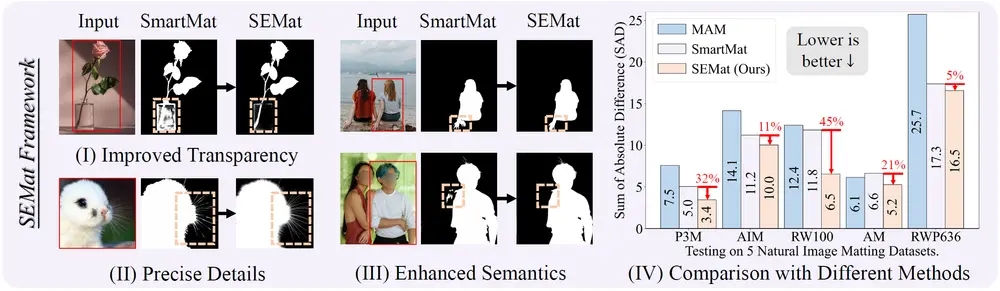
在七个不同数据集上的广泛实验表明,SEMat 在交互式自然图像抠图任务中表现出优越的性能,证明了其有效性和鲁棒性。
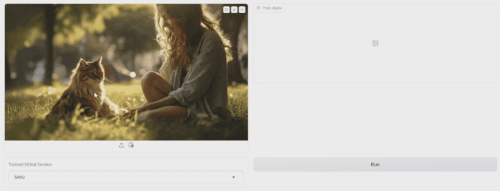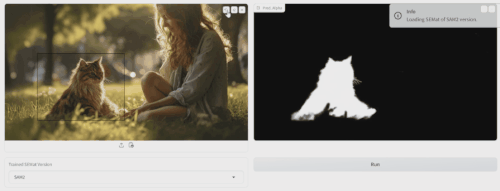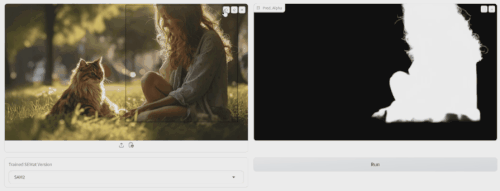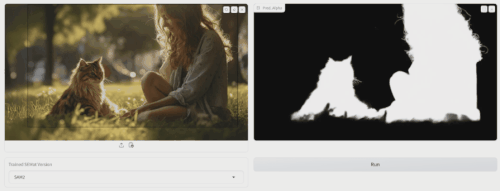
应用场景
- 图像编辑:用户可以拍摄一张照片,背景杂乱,希望只保留照片中的人物或物体,而去除或替换背景。SEMat 技术能够智能地分辨出哪些部分是前景对象,哪些是背景,生成一个透明度图(alpha matte),告诉图像编辑软件哪些部分需要保留,哪些可以修改或删除。
- 视频编辑:在视频编辑中,SEMat 可以用于实时抠图,将演员从一个背景中抠出并放置到另一个背景中,适用于电影制作、广告和直播等领域。
- AR/VR:在增强现实和虚拟现实应用中,SEMat 可以用于实时抠图,将用户融入虚拟环境中,提供沉浸式体验。
SEMat 通过构建新的 COCO-Matting 数据集和改进的网络架构及训练目标,显著提升了交互式自然图像抠图的性能。其精确的边缘和透明度特征提取、针对性的对象分割和无需微调的特点,使其在图像和视频编辑、AR/VR 等领域具有广泛的应用前景。希望 SEMat 能够成为图像处理和计算机视觉领域的有力工具。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











