
可控人物图像生成的目标是根据参考图像生成高质量的人物图像,同时允许对人物的外观或姿势进行精确控制。尽管现有的方法在整体图像质量上取得了显著进展,但它们往往会在生成过程中扭曲参考图像中的细粒度纹理细节。这种扭曲主要归因于模型在训练期间未能充分关注参考图像中的相应区域。

为了解决这一问题,Meta AI、伦敦国王学院和同济大学的研究人员提出了 Leffa(Learning Flow Fields in Attention),这是一种新的方法,旨在通过显式引导目标查询在注意力层中关注正确的参考键来减少细节扭曲。Leffa 通过引入正则化损失来实现这一点,该损失作用于基于扩散的基线模型的注意力图之上。Leffa即在学习注意力中的流场以实现可控的人物图像生成。这项研究旨在通过参考图像生成人物图像,允许对人物的外观或姿势进行精确控制。具体来说,这项技术可以应用于虚拟试穿衣物或姿势转换等场景,同时减少细节失真,保持高图像质量。
- GitHub:https://github.com/franciszzj/Leffa
- 模型:https://huggingface.co/franciszzj/Leffa
- Demo:https://huggingface.co/spaces/franciszzj/Leffa
- Comfyui插件:https://github.com/StartHua/Comfyui_leffa
例如,在虚拟试穿场景中,用户可能希望在不实际穿上衣物的情况下,看到某件衣服穿在自己身上的效果。通过这项技术,系统可以生成用户穿着特定衣物的图像,同时保持用户原有面貌的细节特征。另一个例子是姿势转换,系统可以根据一张人物正面照片生成该人物侧身或背面的姿势图像。
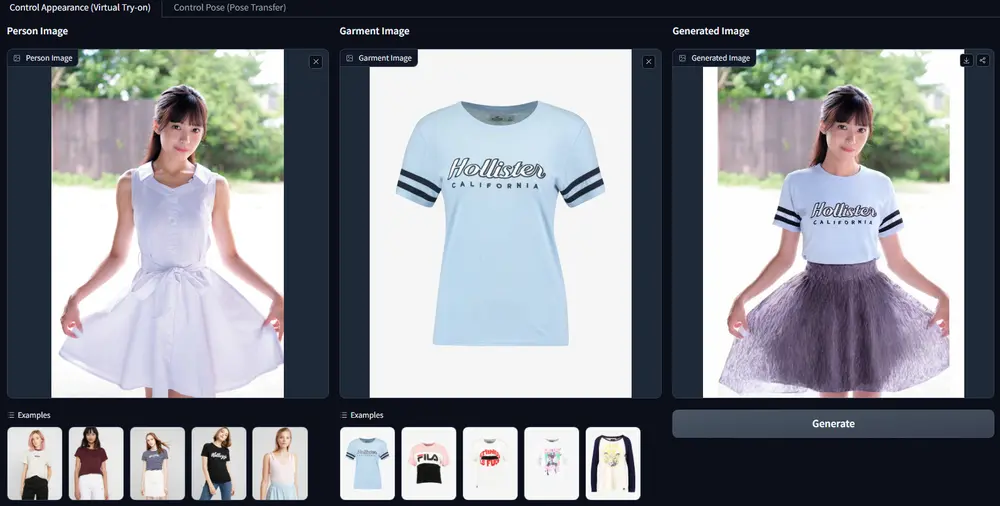
Leffa 的核心技术
显式引导注意力:
- 流场学习:Leffa 的核心思想是在训练过程中引入一个 流场,该流场指导注意力机制将目标查询与参考图像中的正确区域对齐。具体来说,流场定义了从目标图像到参考图像的空间映射,确保每个目标查询能够准确地关注到参考图像中的对应位置。
正则化损失:
- 注意力图上的损失:为了确保流场的有效性,研究人员在注意力图上引入了一个 正则化损失。这个损失函数鼓励注意力机制在生成过程中更多地关注参考图像中的细粒度细节,从而减少扭曲。具体来说,损失函数会惩罚那些未能正确对齐的注意力权重,迫使模型更精确地捕捉参考图像中的特征。
模型无关性:
- 适用于其他扩散模型:Leffa 的设计使得它不仅适用于特定的扩散模型,还可以用于提高其他扩散模型的性能。这意味着研究人员可以在不同的生成任务中应用 Leffa,而无需重新设计整个模型架构。
主要功能和特点
- 外观和姿势控制:该技术能够根据参考图像生成人物图像,精确控制人物的外观(如衣物试穿)和姿势(如姿势转换)。
- 减少细节失真:通过学习注意力中的流场,该技术显著减少了从参考图像中复制的细粒度细节(如纹理、文字、标志等)的失真。
- 高图像质量:在保持细节的同时,生成的图像整体质量高。
- 模型无关性:提出的Leffa(Learning flow fields in attention)损失函数可以用于改善其他扩散模型的性能,具有很好的通用性。
工作原理
Leffa通过在训练期间对注意力层中的注意力图施加正则化损失来实现。具体来说,它将目标查询和参考键之间的注意力图转换为流场,这个流场在训练期间扭曲参考图像,使其更紧密地与目标图像对齐。这个过程鼓励目标查询准确地关注正确的参考键区域。通过这种方式,模型在学习生成图像时能够更好地保留来自参考图像的细粒度细节。

实验结果与优势
- 减少细粒度细节扭曲:广泛的实验表明,Leffa 在控制外观(如虚拟试穿)和姿势(如姿势转移)方面达到了最先进的性能。特别是在处理细粒度细节时,Leffa 显著减少了扭曲,生成的图像更加逼真和自然。
- 保持高图像质量:尽管引入了额外的正则化损失,Leffa 仍然能够保持生成图像的整体质量。实验结果显示,Leffa 生成的图像在视觉上与现有方法相当,甚至在某些情况下表现更好。
- 灵活性与可扩展性:由于 Leffa 是模型无关的,它可以轻松集成到其他扩散模型中,进一步扩展了其应用范围。研究人员展示了 Leffa 在多个生成任务中的有效性,证明了其广泛适用性。
应用场景
Leffa 在多个应用场景中具有广泛的应用潜力,包括但不限于:
- 虚拟试穿:用户可以上传自己的照片,并选择不同的服装款式,Leffa 能够生成穿着这些服装的逼真图像,帮助用户更好地预览效果。
- 姿势转移:用户可以上传一张自己站立的照片,并选择一个不同的姿势,Leffa 能够生成用户以新姿势站立的图像,同时保持面部和其他细节的准确性。
- 影视制作:导演和制片人可以使用 Leffa 生成符合剧本要求的角色形象,快速调整角色的外观或动作,节省时间和成本。
- 广告和营销:品牌可以通过 Leffa 生成个性化的广告图像,展示不同风格的产品或服务,吸引用户的注意力并提高品牌知名度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











