
英伟达、麻省理工学院和清华大学的研究人员推出新型文本到图像生成框架SANA,它能够高效地生成高达4096×4096分辨率的高清晰度图像。SANA的核心优势在于它不仅生成的图像质量高,而且与文本的匹配度强,同时在笔记本电脑的显卡上也能快速运行,这使得它在多种设备上都能部署,为内容创作提供了低成本的解决方案。
- 项目主页:https://nvlabs.github.io/Sana
- GitHub:https://github.com/NVlabs/Sana
- Demo:https://nv-sana.mit.edu
- 模型:https://huggingface.co/collections/Efficient-Large-Model/sana-673efba2a57ed99843f11f9e
- ComfyUI插件:https://github.com/NVlabs/Sana/blob/main/asset/docs/ComfyUI/comfyui.md
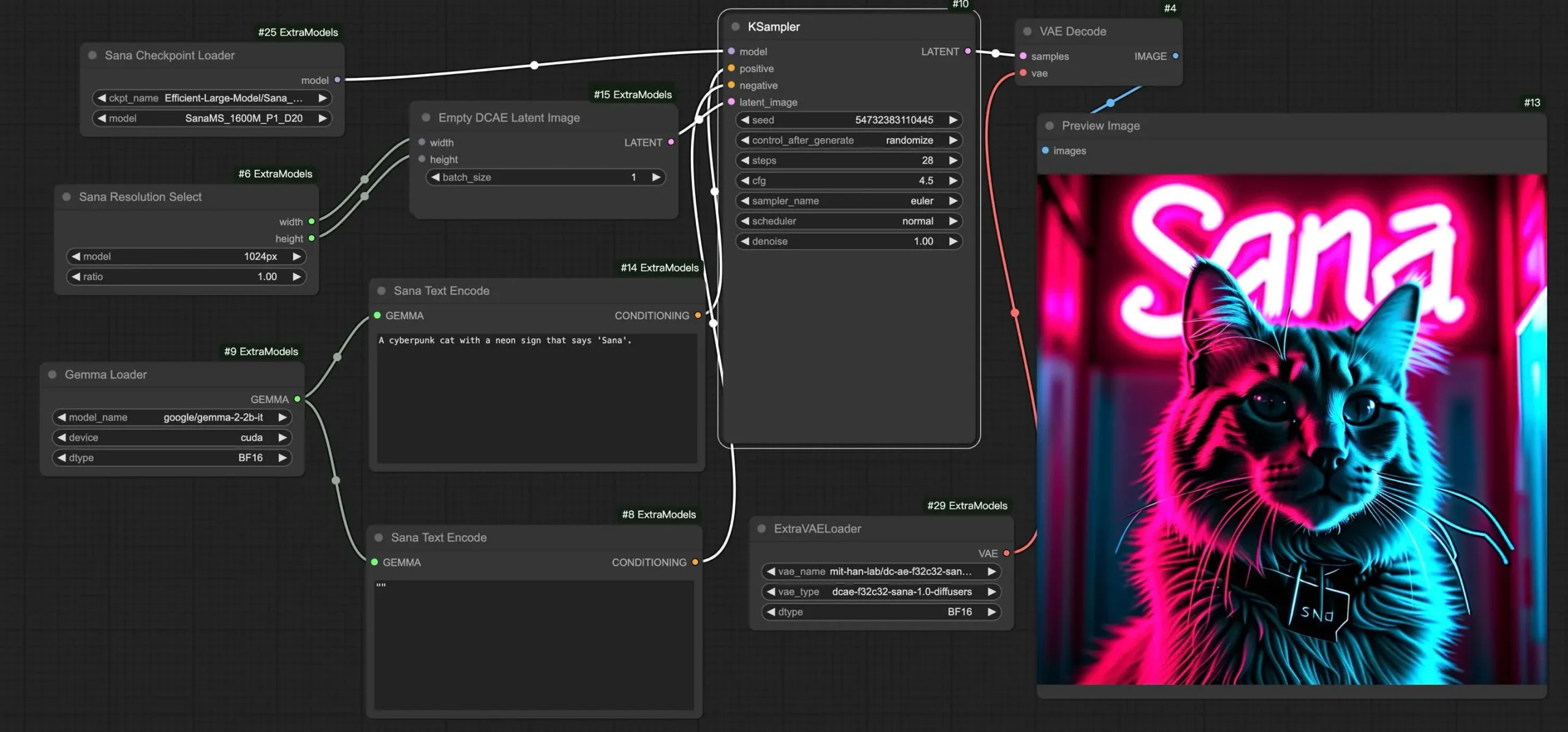
Sana其核心设计包括以下几个方面:
深度压缩自动编码器:与传统自动编码器(AE)仅能压缩图像8倍不同,我们训练了一个能够压缩图像32倍的AE,从而大幅减少了潜在Token的数量。 线性DiT:我们将DiT中的所有普通注意力替换为线性注意力,这种改进在高分辨率下更为高效,同时不牺牲图像质量。 仅解码器的文本编码器:我们用现代的仅解码器小大语言模型(LLM)替换了T5作为文本编码器,并通过上下文学习设计复杂的人类指令,以增强图像与文本之间的对齐效果。 高效的训练和采样:我们提出了Flow-DPM-Solver来减少采样步骤,并通过高效的标题标注和选择来加速模型的收敛。
结果显示,Sana-0.6B在性能上与现代巨型扩散模型(如Flux-12B)不相上下,但其体积小了20倍,测量吞吐量快了100倍以上。此外,Sana-0.6B可以在16GB笔记本电脑GPU上运行,生成1024×1024分辨率的图像仅需不到1秒。Sana的推出使得内容创作变得更加经济实惠。值得注意的是此框架的第一作者同时也是之前介绍的PixArt系列系列的作者。

主要功能:
- 高分辨率图像生成:SANA能够生成高达4096×4096像素的图像,这意味着你可以得到非常清晰的图片。
- 文本到图像的转换:你只需要提供一段描述性的文本,SANA就能理解并生成匹配的图像。
- 快速生成:即使是在笔记本电脑上,SANA也能迅速生成图像,大大减少了等待时间。
主要特点:
- 深度压缩自动编码器:SANA使用了一个特殊的自动编码器来压缩图像,减少了需要处理的数据量,从而加快了生成速度。
- 线性注意力机制:SANA在处理图像时使用了线性注意力机制,这使得它在处理高分辨率图像时更加高效。
- 小型解码器-only的语言模型:SANA使用了一种小型的语言模型来理解文本,这有助于提高图像与文本的匹配度。
- 高效的训练和采样策略:SANA通过一些特殊的训练技巧,减少了生成图像所需的计算步骤,进一步提高了效率。
工作原理:
SANA通过一个深度压缩的自动编码器将图像压缩,然后使用一个线性注意力机制的Transformer模型来逐步去除噪声,最终生成清晰的图像。同时,它使用一个小型的语言模型来理解用户提供的文本描述,并将其转化为图像生成的指导信息。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
![黑森林实验室发布 FLUX.2 [klein] 9B-KV:多参考图像编辑速度飙升 2.5 倍](https://pic.sd114.wiki/wp-content/uploads/2026/03/1773338443-1773338443-FLUX.webp~tplv-o4t1hxlaqv-image.image)



暂无评论...











