Yandex Research 推出了一种名为 “Scale-wise Distillation of Diffusion Models (SWD)” 的新型框架,通过分层采样策略加速扩散模型(DMs)的生成过程。与传统的全分辨率模型相比,SWD 在保持甚至提高图像质量的同时,实现了显著的速度提升(2.5 倍至 10 倍)。
传统扩散模型的局限性
传统的扩散模型(如FLUX和SD3.5)在生成高分辨率图像时,需要在目标分辨率下逐步去噪,生成高质量图像。然而,这个过程非常耗时,通常需要 20-50 个去噪步骤。例如,生成一张 1024×1024 的图像可能需要数十个步骤,每个步骤都需要大量的计算资源。

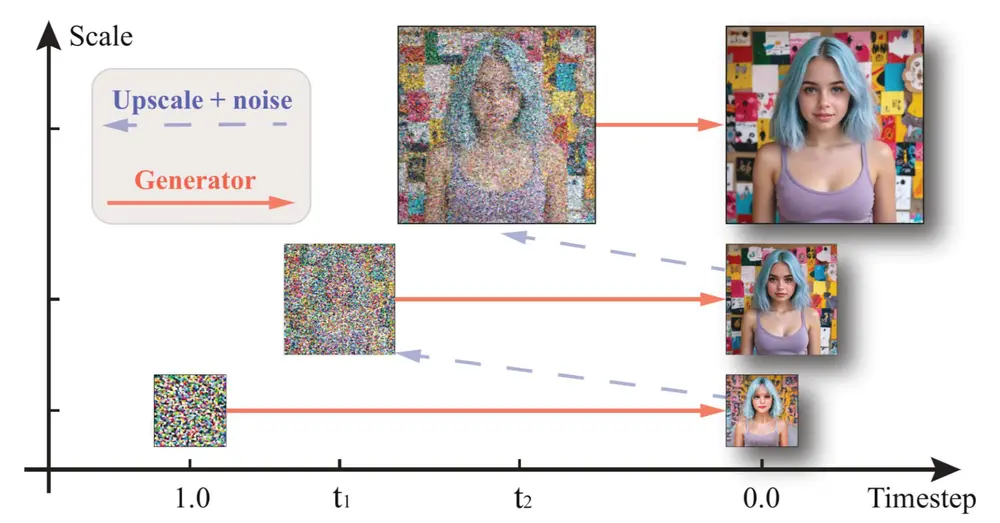
SWD 框架通过在扩散过程中逐步增加图像的分辨率,而不是一开始就从高分辨率开始,从而显著减少了计算量和生成时间。具体来说,SWD 从较低的分辨率(如 256×256)开始,逐步增加到目标分辨率(如 1024×1024),从而在更少的步骤内生成高质量的图像。
- 项目主页:https://yandex-research.github.io/swd
- GitHub:https://github.com/yandex-research/swd
- Demo:https://huggingface.co/spaces/dbaranchuk/Scale-wise-Distillation
Yandex Research 目前发布了两个版本的 SWD,分别是 Medium(2B)和 Large(8B),它们均基于 SD3.5。实验结果表明,SWD 在保持甚至提高图像质量的同时,实现了显著的速度提升。具体来说:
速度提升:与传统的全分辨率模型相比,SWD 实现了 2.5 倍至 10 倍的速度提升。 图像质量:通过创新的训练方法和损失函数,SWD 确保生成图像的质量与全分辨率模型相当甚至更好。
| 模型 | Scales | Sigmas |
|---|---|---|
| SwD 2B, 6 steps | 32, 48, 64, 80, 96, 128 | 1.0000, 0.9454, 0.8959, 0.7904, 0.7371, 0.6022, 0.0000 |
| SwD 2B, 4 steps | 32, 64, 96, 128 | 1.0000, 0.9454, 0.7904, 0.6022, 0.0000 |
| SwD 8B, 6 steps | 32, 48, 64, 80, 96, 128 | 1.0000, 0.9454, 0.8959, 0.7904, 0.7371, 0.6022, 0.0000 |
| SwD 8B, 4 steps | 64, 80, 96, 128 | 1.0000, 0.8959, 0.7371, 0.6022, 0.0000 |
SWD 的核心设计
SWD 主要依赖于两个关键超参数:scales 和 sigmas。
scales 超参数:定义了生成过程中使用的空间分辨率序列,比如从较低的分辨率(如 256×256)逐步过渡到最终的目标分辨率(如 1024×1024),使得模型能够在早期阶段专注于全局结构,而在后期阶段聚焦于细节优化。 sigmas 超参数:控制扩散过程中每一步应用的噪声水平,相当于调整扩散的时间步长,有助于更高效地完成去噪过程,并减少伪影。
主要功能
1. 加速扩散模型的生成
分层采样策略:SWD 通过分层采样策略,在更少的步骤内生成高质量的图像,显著降低了计算成本。 显著的速度提升:与传统的全分辨率模型相比,SWD 实现了 2.5 倍至 10 倍的速度提升,大大减少了生成高分辨率图像所需的时间。
2. 保持生成质量
创新的训练方法:SWD 通过创新的训练方法和损失函数,确保生成图像的质量与全分辨率模型相当甚至更好。 优化的生成过程:通过分层采样和时间表偏移,SWD 在减少计算量的同时,保持了生成图像的高质量。
3. 兼容多种扩散模型
通用性:SWD 可以应用于现有的扩散模型架构,如基于 Transformer 的模型,具有良好的通用性。 灵活的扩展:SWD 框架可以轻松扩展到不同的模型和任务中,适用于多种应用场景。
主要特点
1. 分层采样策略
逐步增加分辨率:在扩散过程中,SWD 从低分辨率开始,逐步增加到高分辨率,从而在更少的步骤内生成高质量的图像。 减少计算量:通过逐步增加分辨率,SWD 显著减少了计算量和生成时间。
2. 时间表偏移
减少伪影:通过将扩散过程中的时间步调整到更高的噪声水平,SWD 减少了上采样带来的伪影,进一步优化了生成图像的质量。
3. Patch Distribution Matching (PDM) 损失
优化生成质量:SWD 引入了一种新的损失函数 PDM,通过最小化空间 token 分布之间的距离来优化生成图像的质量。 分布匹配:PDM 损失确保生成图像与目标图像在空间分布上高度一致,从而提升生成图像的视觉效果。
4. 训练与生成的双重优化
快速生成:SWD 通过训练一个同时具备上采样能力的模型,提高了生成图像的速度。 高质量上采样:通过分布匹配损失和 GAN 损失等优化目标,SWD 确保生成图像的质量与全分辨率模型相当甚至更好。
工作原理
1. 分层采样
时间表和分辨率表:SWD 定义了一个时间表和一个对应的分辨率表。在每个去噪步骤中,模型从低分辨率的噪声图像开始,逐步增加分辨率,最终生成高分辨率的清晰图像。 逐步去噪:通过逐步增加分辨率,SWD 在更少的步骤内完成去噪过程,显著减少了计算量。
2. 时间表偏移
调整时间步:通过将扩散过程中的时间步调整到更高的噪声水平,SWD 减少了上采样带来的伪影,进一步优化了生成图像的质量。
3. PDM 损失
最小化分布距离:通过最小化生成图像和目标图像的空间 token 分布之间的距离,PDM 损失优化了生成图像的质量。 提升视觉效果:PDM 损失确保生成图像与目标图像在空间分布上高度一致,从而提升生成图像的视觉效果。
4. 训练过程
合成数据训练:SWD 使用合成数据进行训练,通过分布匹配损失和 GAN 损失等优化目标,训练一个能够同时进行快速生成和高质量上采样的模型。 双重优化:SWD 不仅优化了生成过程,还通过训练一个同时具备上采样能力的模型,提高了生成图像的质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...