
扩散模型(Diffusion Models)近年来在图像生成和视频生成领域表现出色,但其计算复杂度也成为了性能瓶颈。特别是基于DiT架构的模型,如FLUX、HunyuanVideo 等,其注意力层和多层感知机(MLP)层的计算开销往往占据主要资源。
为了解决这一问题,Sandy Research 提出了 Chipmunk,一种无需训练、硬件感知的动态稀疏性方法,通过缓存和稀疏计算显著加速DiT模型的推理过程。这种方法无需额外训练,通过缓存前几步的注意力权重和 MLP 激活,并动态计算相对于缓存权重的稀疏“delta”,实现了显著的性能提升。

性能表现
Chipmunk 在多个任务中展现了卓越的加速效果:
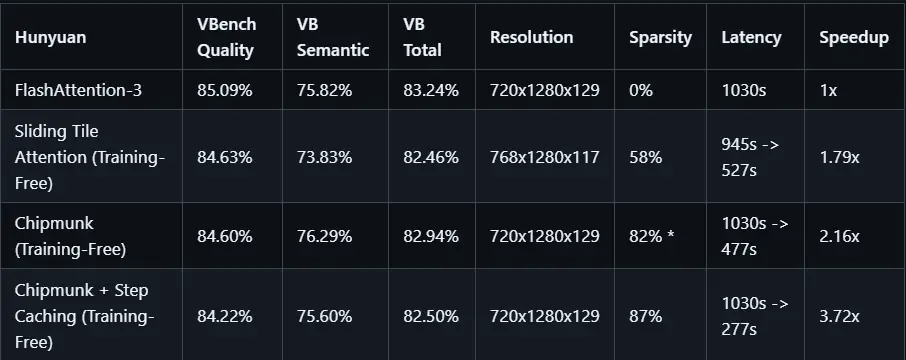
- 视频生成:在 720x1280 分辨率下生成 5 秒视频(50 步)时,Chipmunk 在 HunyuanVideo 上实现了高达 3.7 倍 的加速。
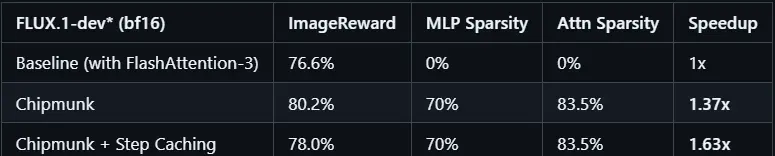
- 图像生成:在 1280x768 分辨率下生成 FLUX.1-dev 图像(50 步)时,实现了 1.6 倍 的加速。
- 稀疏注意力层:比 FlashAttention3 基线快约 9.3 倍。
- 稀疏 MLP 层:比 cuBLAS 基线快约 2.5 倍。
工作原理
Chipmunk 的核心思想基于对 DiT 架构模型的两个经验观察:
- 激活在时间步长上缓慢演变:模型的激活值在连续的时间步长之间变化较小。
- 注意力权重和 MLP 激活高度稀疏:这些权重和激活值中大部分是零或接近零。
基于这些观察,Chipmunk 采用了以下策略:
- 缓存机制:缓存第
- 动态“delta”计算:在第
为了充分利用 GPU 的硬件特性,Chipmunk 将这些“delta”映射到与硬件 GEMM 核对齐的块稀疏模式(例如,128×256 瓦片)。它跳过整个块而不是单个元素,从而实现高效的 [128×1] 列稀疏性。同时,Chipmunk 动态重新排序键、值和标记,确保稀疏行在每个瓦片内密集打包,保持连续的内存访问。
技术细节
- 列稀疏模式:Chipmunk 使用 [128, 1] 和 [192, 1] 列稀疏模式,这些模式与 GPU 的硬件特性高度匹配,显著提高了计算效率。
- 优化的稀疏注意力机制和 MLP CUDA 核:Chipmunk 通过优化稀疏注意力机制和 MLP 的 CUDA 核,实现了硬件高效性。这些优化确保了在稀疏计算中充分利用 GPU 的并行计算能力。
- 动态稀疏性:Chipmunk 动态计算相对于缓存权重的稀疏“delta”,避免了不必要的计算。这种方法不仅减少了计算量,还提高了内存访问效率。
- 硬件感知设计:Chipmunk 的设计充分考虑了硬件特性,通过块稀疏模式和连续内存访问,最大化利用 GPU 的计算能力。
优势总结
Chipmunk 的主要优势包括:
- 无需训练:无需额外的训练过程,直接应用于现有模型。
- 显著加速:在视频和图像生成任务中实现了显著的加速效果。
- 硬件高效性:通过优化的稀疏模式和 CUDA 核,充分利用 GPU 的硬件特性。
- 动态稀疏性:动态计算稀疏“delta”,减少不必要的计算,提高效率。
适用场景
Chipmunk 适用于以下场景:
- 视频生成:在高分辨率下快速生成高质量视频。
- 图像生成:在高分辨率下快速生成高质量图像。
- 实时应用:需要快速响应的实时生成任务。
- 资源受限环境:在计算资源有限的情况下,实现高效的模型加速。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











