
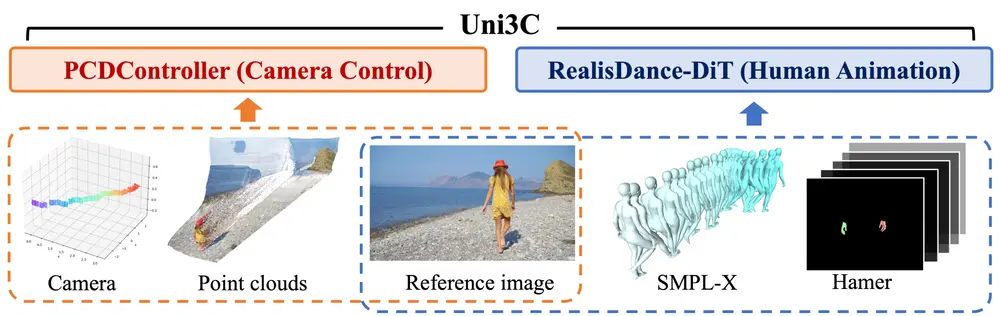
阿里达摩院、复旦大学和湖畔实验室的研究人员推出新型框架Uni3C,旨在通过3D增强技术实现对视频生成中相机和人体运动的精确控制。Uni3C通过将相机控制和人体运动控制统一到一个框架中,解决了现有方法中这两方面通常被分开处理的问题,从而提高了视频生成的可控性和质量。

主要功能
- 精确的相机控制:Uni3C能够根据给定的相机轨迹生成高质量的视频内容。例如,给定一个单视角图像和一系列目标相机轨迹,Uni3C可以生成与这些轨迹一致的视频。
- 人体运动控制:Uni3C支持基于SMPL-X模型的人体动画控制。用户可以指定人体的动作序列,Uni3C能够生成相应的人体运动视频。
- 联合控制:Uni3C能够同时控制相机轨迹和人体运动,生成两者协同的视频内容。例如,可以生成一个人物在复杂环境中按照指定轨迹移动的视频。
- 运动转移:Uni3C支持将一个视频中的人物动作转移到另一个视频中,同时保持相机轨迹的控制。
主要特点
- 轻量级控制模块:Uni3C提出了一个轻量级的控制模块 PCDController,仅包含0.95亿参数,相比基础视频生成模型(如Wan2.1,包含140亿参数)大幅减少。这使得PCDController能够高效地控制相机轨迹,同时保持对基础模型的兼容性。
- 3D几何先验:PCDController利用从单目深度图中提取的点云作为3D几何先验,显著提高了相机控制的精度和鲁棒性。
- 全局3D世界引导:Uni3C通过将场景点云和SMPL-X人物对齐到同一个3D世界坐标系中,实现了相机和人体运动的统一控制。这种对齐方式确保了生成的视频在3D空间中的一致性。
- 强大的泛化能力:PCDController在多种下游任务中表现出色,包括图像到视频(I2V)和文本到视频(T2V)生成任务,展示了其强大的泛化能力。
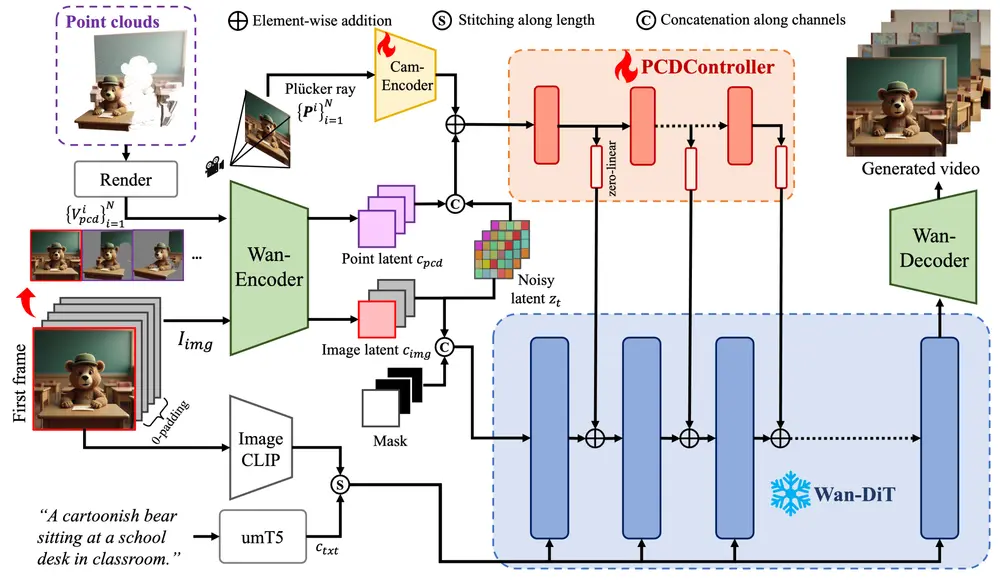
工作原理
PCDController:
- 架构:PCDController基于简化的扩散模型(DiT)构建,避免了对基础视频生成模型的深度修改。它通过从单目深度图中提取的点云来控制相机轨迹。
- 3D几何先验:通过从参考图像中提取单目深度图,将2D像素反投影到3D世界坐标系中,生成点云。这些点云作为相机控制的主要信号,显著提高了相机轨迹的精度。
- 训练策略:PCDController在训练时仅使用点云和Plücker射线作为条件,避免了对基础模型的过度依赖,从而提高了泛化能力。
全局3D世界引导:
- 多模态对齐:Uni3C将场景点云和SMPL-X人物对齐到同一个3D世界坐标系中。通过2D关键点的刚性变换,将SMPL-X人物从人物世界空间对齐到环境世界空间。
- 重力校准:使用GeoCalib技术校准SMPL-X人物的重力方向,确保人物运动的合理性。
- 联合控制:在推理阶段,将对齐后的点云和人物作为全局3D世界引导,生成与相机轨迹和人物运动一致的视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











