
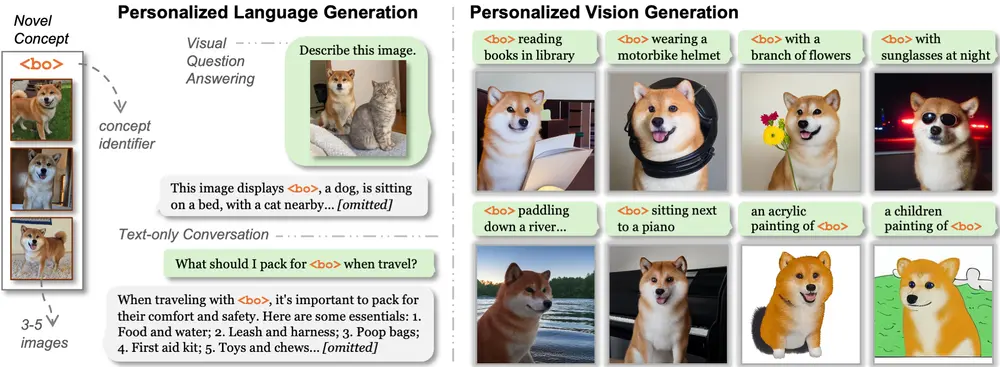
威斯康星大学麦迪逊分校和Adobe Research的研究人员推出新型框架Yo’Chameleon,为大型多模态模型(LMMs)实现个性化视觉和语言生成能力。Yo’Chameleon 通过软提示调优(soft-prompt tuning)技术,使模型能够根据用户提供的少量图像(3-5张)学习特定概念,并生成高质量的个性化文本和图像。例如,用户可以提供几张宠物狗的照片,Yo’Chameleon 能够生成关于这只狗的详细描述,并在新的场景中生成该狗的图像。
假设你有一只名叫“Bo”的狗,你希望 AI 助手能够生成关于“Bo”的描述和图像。你可以提供几张“Bo”的照片,Yo’Chameleon 会学习这些照片中的视觉特征,并生成如“Bo is a fluffy dog with a round face and a mix of light and dark brown colors”这样的描述,同时还能生成“Bo”在不同场景中的图像,比如“Bo”在图书馆读书或在河边划船的图像。
主要功能
- 个性化语言生成:Yo’Chameleon 能够根据用户提供的少量图像生成详细的文本描述。
- 个性化图像生成:Yo’Chameleon 能够在新的场景中生成用户特定概念的图像。
- 多模态理解与生成:Yo’Chameleon 支持视觉问答和图像识别任务,能够理解图像内容并生成相关文本。
主要特点
- 软提示调优(Soft-Prompt Tuning):通过引入可学习的提示(prompt)来编码新概念,而无需对整个模型进行微调,从而避免灾难性遗忘(catastrophic forgetting)。
- “软正样本”(Soft-Positive)图像:利用与正样本视觉相似的图像作为“软正样本”,并根据其相似度分配不同的提示长度,增强训练数据的多样性和质量。
- 自提示机制(Self-Prompting):模型在生成响应之前先预测任务类型(理解或生成),从而更好地利用适当的提示令牌。
- 高效学习:使用较少的提示令牌(32个)即可实现高效的个性化学习,相比传统的详细文本提示或图像提示,显著减少了计算成本。
工作原理
Yo’Chameleon 的工作原理基于以下三个核心部分:
- 概念表示为可学习提示:将个性化概念表示为可学习的提示,例如“<sks> is <token1><token2>...<tokenk>”,其中 <sks> 是概念的唯一标识符,<tokeni> 是编码视觉信息的可学习令牌。
- 个性化图像生成:通过“软正样本”图像增强训练数据的多样性。这些图像与正样本具有不同程度的视觉相似性,模型根据相似度分配不同的提示长度,从而更有效地学习目标概念的特征。
- 自提示机制:在生成响应之前,模型首先预测任务类型(理解或生成),并选择相应的提示令牌。这种方法使模型能够更好地平衡多模态任务的性能。

应用场景
- 智能助手:Yo’Chameleon 可以集成到智能助手中,使助手能够根据用户的个性化需求生成文本和图像。例如,用户可以要求助手生成特定宠物或物品的描述和图像。
- 内容创作:在内容创作领域,Yo’Chameleon 可以帮助创作者快速生成符合特定风格或主题的图像和文本,提高创作效率。
- 教育和培训:Yo’Chameleon 可以用于教育和培训场景,生成个性化的学习材料,如特定对象的描述和示例图像。
- 社交媒体:用户可以利用 Yo’Chameleon 生成个性化的图像和文本内容,用于社交媒体分享。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











