
微软发布了一个名为 BitNet v2 的新型框架,旨在为 1-bit 大型语言模型(LLMs)实现原生 4-bit 激活量化。该框架通过引入 H-BitLinear 模块,解决了在低比特量化中激活值异常(outliers)的问题,从而显著提高了模型的内存效率和计算效率。BitNet v2 在保持与 BitNet b1.58 相当性能的同时,大幅减少了内存占用和计算成本,尤其在批量推理场景中表现出色。
例如,在处理自然语言处理任务时,如机器翻译或文本生成,BitNet v2 可以将模型的激活值从 8-bit 量化到 4-bit,从而在不显著降低性能的情况下,显著减少模型的内存占用和计算量。这使得模型可以在资源受限的设备上更高效地运行,同时保持较高的推理速度。(相关:微软发布20亿参数1-bit模型BitNet b1.58,性能超越主流LLM且更适合边缘设备)
主要功能
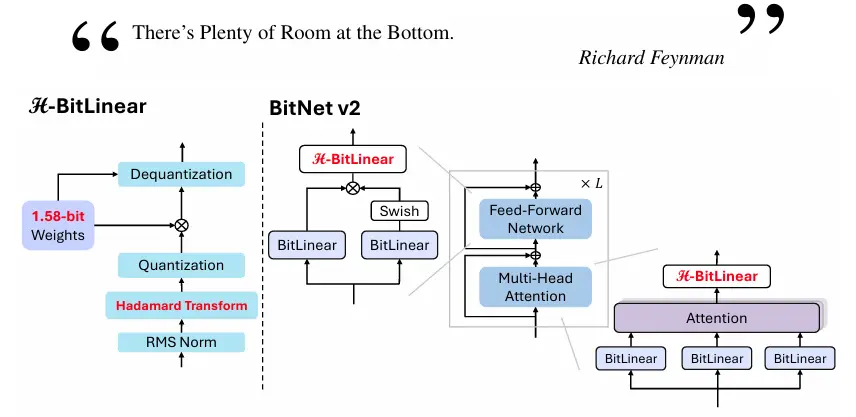
- 原生 4-bit 激活量化:BitNet v2 通过 H-BitLinear 模块,将激活值从 8-bit 量化到 4-bit,显著减少了内存占用和计算成本。
- Hadamard 变换:通过在线 Hadamard 变换,将激活值的分布从尖锐的异常值分布转换为更接近高斯分布的形式,使其更适合低比特量化。
- 高效推理:BitNet v2 在批量推理场景中表现出色,能够充分利用现代硬件的 4-bit 计算能力,显著提高推理效率。
主要特点
- H-BitLinear 模块:通过在线 Hadamard 变换,有效抑制激活值中的异常值,使激活值分布更接近高斯分布,从而更适合低比特量化。
- 混合精度训练:使用混合精度训练技术,结合直通过估计器(STE)进行梯度近似,确保模型在低比特量化下的训练稳定性。
- 灵活的量化策略:支持多种量化策略,包括 4-bit 和 8-bit 激活值的混合使用,以及权重的 1.58-bit 量化。
- 高效推理:通过 4-bit 激活值的使用,显著减少了内存占用和计算成本,尤其在批量推理场景中表现出色。
工作原理
BitNet v2 的工作原理基于以下三个核心部分:
- H-BitLinear 模块:在注意力模块的输出投影(Wo)和前馈网络(FFN)的下投影(Wdown)中引入 H-BitLinear 模块。该模块在激活量化之前应用在线 Hadamard 变换,将尖锐的激活值分布转换为更接近高斯分布的形式,从而减少异常值的影响。
- 激活量化:对于 8-bit 和 4-bit 激活值,分别采用 per-token absmax 和 absmean 函数进行量化。量化后的激活值通过 H-BitLinear 模块进行矩阵乘法运算。
- 混合精度训练:使用混合精度训练技术,结合直通过估计器(STE)进行梯度近似,确保模型在低比特量化下的训练稳定性。在反向传播中,Hadamard 变换的梯度通过其正交性进行传播。
具体应用场景
- 自然语言处理:BitNet v2 可以应用于各种自然语言处理任务,如机器翻译、文本生成、问答系统等。通过 4-bit 激活值的使用,模型可以在资源受限的设备上更高效地运行,同时保持较高的推理速度。
- 边缘设备:在边缘设备上部署大型语言模型时,BitNet v2 的低比特量化能力可以显著减少内存占用和计算成本,使其更适合在资源受限的环境中运行。
- 实时推理:在需要实时推理的场景中,如智能助手和语音交互系统,BitNet v2 的高效推理能力可以显著提高系统的响应速度和用户体验。
总结
BitNet v2 通过引入 H-BitLinear 模块,解决了低比特量化中激活值异常的问题,实现了原生 4-bit 激活量化。该框架在保持与 BitNet b1.58 相当性能的同时,显著减少了内存占用和计算成本,尤其在批量推理场景中表现出色。BitNet v2 的高效推理能力和灵活的量化策略使其在自然语言处理、边缘设备和实时推理等场景中具有广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











