
在当今的文本到图像生成领域,尽管模型在生成视觉上吸引人的图像方面取得了显著进步,但在处理精确且灵活的排版元素时,尤其是对于非拉丁字母,仍然存在明显的局限性。这种局限性主要源于文本编码器在处理多语言输入时的不足,以及训练集中多语言数据分布的偏差。为了实现特定语言的文本渲染,一些研究尝试使用专用的文本编码器或多语言大型语言模型替换现有的单语编码器,并重新训练模型,但这不仅耗时耗力,还导致了高昂的资源消耗。另一些研究则通过辅助模块来编码文本和字形,但这些方法大多局限于基于 UNet 的模型,无法充分发挥基于 DiT 的最新模型(如 SD3.5 和 FLUX)的潜力。
- GitHub:https://github.com/Shakker-Labs/RepText
- Demo:https://huggingface.co/spaces/Shakker-Labs/RepText
为了解决这些限制,Liblib AI 旗下的 Shakker Labs 提出了 RepText,这是一个创新的框架,旨在使预训练的单语文本到图像生成模型能够在用户指定的字体中准确渲染多语言视觉文本,而无需真正理解这些文本的含义。RepText 的核心思想是:文本理解只是文本渲染的充分条件,而不是必要条件。
- PS:依照Liblib AI以往做法,此模型不一定会开源;或者等待一段时间才会释出模型。

RepText 的核心优势
- 多语言视觉文本渲染:RepText 能够准确渲染多种语言(包括非拉丁字母)的文本,支持用户指定字体、颜色和位置,满足多样化的视觉设计需求。
- 高精度文本复制:通过引入文本感知损失和扩散损失,RepText 提高了文本渲染的准确性,同时避免了重新训练模型的高成本。
- 兼容性:RepText 与现有的插件模型(如 LoRAs、ControlNets 和 IP-Adapter)无缝集成,可以结合这些工具实现更丰富的功能。
- 无需理解文本:RepText 不依赖于文本编码器对文本内容的理解,而是通过复制字符的视觉特征来实现渲染,从而避免了多语言数据分布偏差的问题。

工作原理
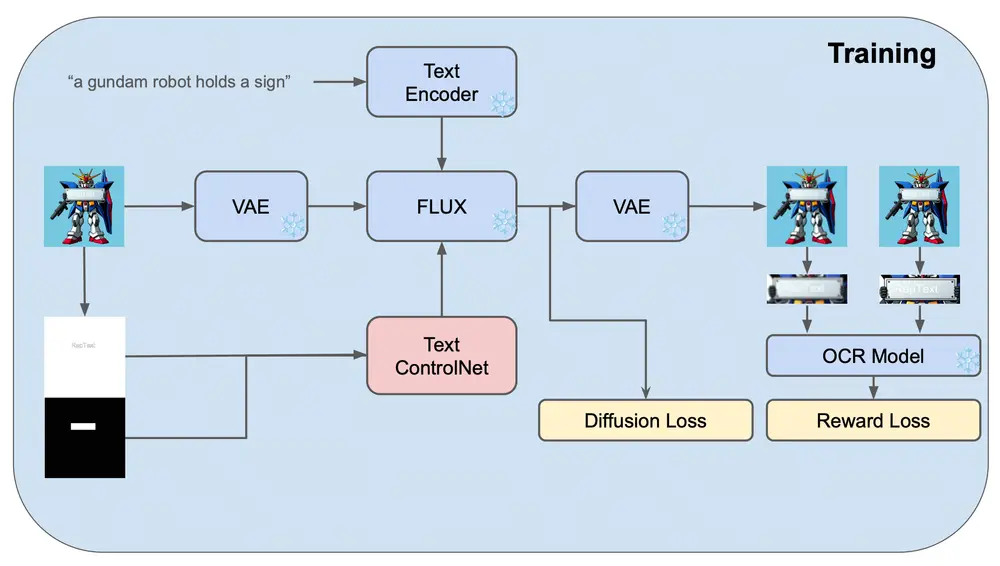
RepText 的设计基于 ControlNet 框架,通过以下创新机制实现高精度的文本渲染:
- 框架设计:
- RepText 使用 Canny 边缘检测和位置图像作为条件,指导模型生成和谐的视觉文本。文本内容通过字符的边缘和位置信息提供给模型,而不是通过文本编码器理解语义。
- 这种设计不仅提高了文本渲染的准确性,还避免了重新训练模型的高成本。
- 文本感知损失:
- 在训练阶段,RepText 使用 OCR 模型(如 PP-OCRv3)来评估生成文本的可识别性,并通过文本感知损失优化模型,提高文本的准确性和可读性。
- 这一机制确保了生成的文本不仅视觉上准确,而且在语义上也易于识别。
- 初始化策略:
- 在推理阶段,RepText 从无噪声的字符潜在表示(glyph latent)初始化,而不是从随机噪声开始。这种复制机制提高了文本的准确性和颜色控制能力。
- 通过这种方式,RepText 能够生成更精确的文本,同时支持用户自定义的颜色和字体。
- 区域掩码:
- 为了防止非文本区域受到干扰,RepText 在推理阶段使用区域掩码,只在文本区域内注入特征,确保背景质量不受影响。
- 这一策略不仅提高了生成图像的整体质量,还避免了背景区域的失真。
实验与结果
通过广泛的实验,RepText 证明了其相对于现有方法的有效性。实验结果表明,RepText 在多语言文本渲染的准确性和图像质量上优于现有的开源方法,并取得了与原生多语言闭源模型相当的结果。此外,RepText 还展示了与现有插件模型(如 LoRAs 和 IP-Adapter)的兼容性,能够结合这些工具实现更丰富的功能。
局限性与未来展望
尽管 RepText 在多语言文本渲染方面取得了显著进展,但它仍然存在一些局限性。例如,对于某些复杂排版或高度风格化的文本,RepText 可能需要进一步优化。此外,RepText 的性能在某些极端情况下(如极低分辨率或极小字体)可能受到限制。未来的研究方向可能包括进一步优化复制机制,提高对复杂排版的支持能力,以及探索更高效的初始化策略。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











