厦门大学多媒体可信感知与高效计算教育部重点实验室和腾讯优图实验室的研究人员推出人脸恢复统一框架SVFR,用于解决视频中的人脸恢复问题。人脸恢复(Face Restoration, FR)是图像和视频处理领域的一个关键研究方向,旨在从退化的输入中重建高质量的人脸图像。
尽管在图像人脸恢复方面已经取得了显著进展,但视频人脸恢复(Video FR)由于时间一致性、运动伪影以及高质量视频数据的有限可用性等挑战,仍相对较少被探索。
- 图像FR:例如,使用有效的图像FR方法可以帮助个人照片增强、历史照片修复和法医分析。
- 视频FR:视频FR可以服务于电影修复和监控视频的增强。例如,将一部旧电影中模糊、低分辨率的人脸恢复为高质量、高分辨率的人脸,同时保持人物的身份一致性和时间稳定性。

主要功能
SVFR框架的主要功能是同时处理视频中的人脸盲恢复(BFR)、面部修复(Inpainting)和面部着色(Colorization)任务。这些任务相互补充,共同提升视频恢复的整体质量和时间一致性。
主要特点
- 多任务学习:SVFR通过同时训练多个相关任务(BFR、Inpainting、Colorization),利用任务之间的共享表示来增强有限训练数据的监督,从而提高整体恢复质量。
- 统一的潜在正则化(ULR):引入ULR来确保不同子任务的特定信息能够正确嵌入到共享的潜在空间中,增强模型在不同任务上的性能。
- 面部先验学习:通过面部地标引导模型学习人类面部结构的先验知识,提高恢复视频的保真度。
- 自引用细化(Self-referred Refinement):在推理过程中,通过引用之前生成的帧来细化生成结果,显著提高恢复视频的时间稳定性和连贯性。
工作原理
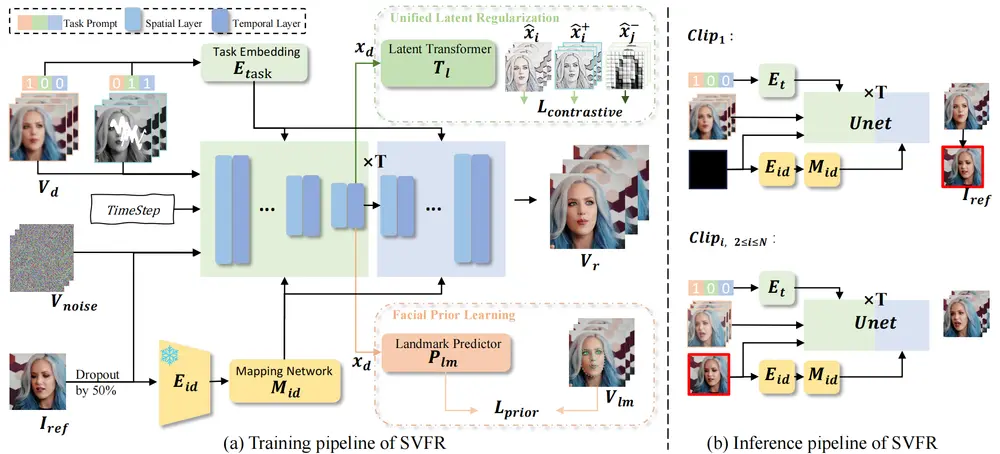
1、Stable Video Diffusion (SVD):SVFR基于预训练的SVD模型,利用其时间稳定的建模能力。SVD通过前向过程将数据逐步转化为高斯噪声,并通过反向过程逐步去除噪声以恢复原始数据。
2、统一人脸恢复框架:
- 任务嵌入(Task Embedding):通过二进制向量表示不同任务,增强模型对特定任务的识别能力。
- 统一潜在正则化(ULR):通过对比损失函数,确保不同任务的中间特征在潜在空间中保持一致,增强结构一致性和减少伪影。
3、面部先验学习:利用面部地标预测器,将面部结构先验知识注入模型,提高面部细节的恢复质量。
4、自引用细化:在训练阶段,通过引用参考帧的特征来增强生成质量;在推理阶段,通过选择之前生成的帧作为参考帧,确保整个视频序列的时间连贯性。
具体应用场景
- 视频会议:在视频会议中,由于网络条件不佳,视频可能会出现模糊、丢包等问题。SVFR可以实时恢复高质量的人脸图像,提高视频会议的视觉效果。
- 电影修复:对于老电影中的人脸图像,SVFR可以修复因年代久远而退化的图像,恢复其原有的高质量和细节,同时保持人物的身份一致性和时间连贯性。
- 监控视频:在监控视频中,由于环境光线、摄像头质量等因素,人脸图像可能会出现模糊、噪声等问题。SVFR可以增强监控视频中的人脸图像,提高监控的准确性和可靠性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











