
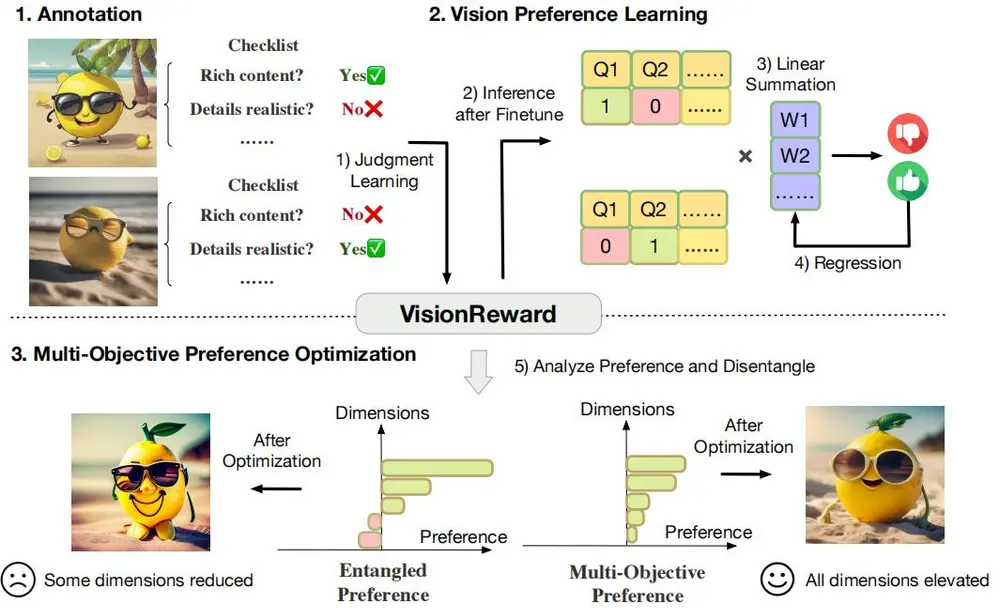
清华大学和智谱AI的研究人员推出VisionReward,这是一个用于图像和视频生成的细粒度多维度人类偏好学习框架。VisionReward通过构建一个细粒度且多维度的奖励模型,将人类对图像和视频的偏好分解为多个维度,每个维度通过一系列判断问题来表示,并通过线性加权和求和生成可解释且准确的评分。该框架特别适用于处理视频质量评估中的动态特征,如运动真实性和运动平滑性。
例如,给定一个文本提示“在古老的图书馆中,一个坚定的年轻女子,红发如火,正在翻阅一本旧书,低声念着咒语”,VisionReward可以评估生成的图像或视频是否符合人类对这一场景的偏好,包括图像的对齐、构图、质量、保真度和安全性等多个维度。
主要功能
- 准确预测人类偏好:在多个数据集上展现出高偏好准确率,如在视频评估中,对长视频的偏好预测表现突出,相比其他方法优势明显。
- 稳定优化视觉生成模型:基于 VisionReward 的 MPO 算法能避免过优化或欠优化问题,有效提升模型性能。
- 视频质量评估:特别适用于评估视频的动态质量,如运动真实性和运动平滑性,超越了现有的视频评分方法。
主要特点
- 细粒度和多维度:将图像和视频的人类偏好分解为多个维度,针对每个维度设计一系列判断问题,全面且细致地评估视觉内容。
- 可解释性:通过线性加权求和得出可解释的分数,能清晰呈现各维度对最终结果的影响。
- 高效处理视频数据:系统分析视频动态特征,在视频偏好预测方面性能优异。
工作原理
- 标注过程:从不同数据源采样图像和视频,设计多维度、多层次的标注体系,将每个维度细分为子维度并设置不同程度的选项,转化为检查表问题用于模型训练。
- VisionReward 训练:基于 CogVLM2 等模型,先对标注的二元判断结果平衡采样,微调模型以回答检查表问题;再通过线性加权回归,利用人类偏好数据学习权重,最小化损失函数得到最优权重。
- 多目标偏好优化(MPO):为解决偏好数据中混杂因素和过优化等问题,将 VisionReward 问题融入维度,定义优势对,根据优势对更新扩散模型梯度,确保各维度合理提升。
具体应用场景
- 图像生成评估与优化:如在艺术创作、广告设计等领域,评估生成图像是否符合人类审美和需求,优化图像生成模型以生成更优质图像。
- 视频生成评估与优化:适用于电影制作、动画设计、短视频创作等场景,对视频质量、内容、动态效果等多方面进行评估和优化,提升视频生成效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











