
昆仑万维的研究人员推出一个强大的框架 Ingredients,通过将多个特定身份(ID)的照片与视频扩散变换器(Video Diffusion Transformers)结合,实现定制化的视频创作。该方法能够在生成的视频中保持多个参考图像中的人脸身份一致性,同时结合用户定义的提示,生成高质量、可编辑且一致的多个人物定制视频。
- GitHub:https://github.com/feizc/Ingredients
- 模型:https://huggingface.co/feizhengcong/Ingredients
- 数据:https://huggingface.co/datasets/feizhengcong/Ingredients
例如,给定一组包含多个人物的参考图像,Ingredients可以生成一个视频,其中每个人物的身份在视频的每一帧中都保持一致,同时根据用户定义的文本提示(如“在公园里散步”)生成相应的动作和场景。
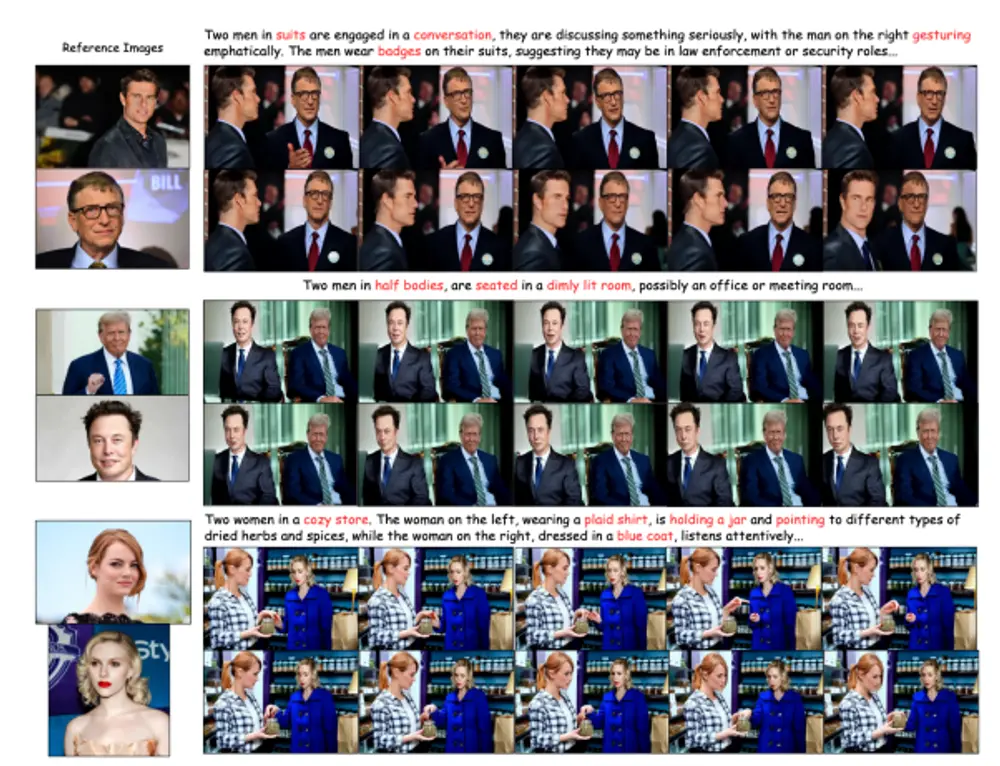
主要功能
- 多ID定制:能够处理多个参考图像,生成包含多个特定人物身份的视频。
- 身份一致性:在生成的视频中保持每个人物的身份一致性。
- 文本提示支持:结合用户定义的文本提示,生成符合提示内容的视频。
- 高质量视频生成:生成的视频具有高质量和自然的视觉效果。

主要特点
- 面部提取器(Facial Extractor):从全局和局部角度提取高保真、可编辑的人脸身份信息,确保视频生成中的人脸一致性。
- 多尺度投影器(Multi-scale Projector):将人脸嵌入映射到视频扩散变换器的上下文空间中,增强模型对人脸特征的感知能力。
- ID路由器(ID Router):动态分配和整合多个ID嵌入到相应的时空区域,避免身份混合,保持个体性。
- 多阶段训练过程:通过面部嵌入对齐阶段和路由器微调阶段,优化人脸嵌入提取和多ID路由,提高生成视频的面部保真度和可控性。
工作原理
1、面部提取器:
- 全局面部嵌入:通过人脸检测提取多个身份的面部区域,合成一个大图像,输入到VAE中提取浅层特征表示。
- 局部面部嵌入:使用人脸识别骨干网络和CLIP图像编码器提取每个身份的特征,保留每个身份的独立特征。
2、多尺度投影器:
- 全局面部嵌入:将全局面部嵌入直接与潜在噪声输入拼接。
- 局部面部嵌入:将多尺度特征与CLIP特征拼接,通过Q-former结构和交叉注意力机制与视频扩散变换器的视觉token进行交互。
3、ID路由器:
- 通过位置感知的路由网络,将每个潜在面部区域分配一个唯一的身份特征。
- 使用分类损失监督路由网络,确保每个区域只分配一个ID特征。
4、训练过程:
- 面部嵌入对齐阶段:优化面部提取器和多尺度投影器,使用LoRA模块增强特征整合。
- 路由器微调阶段:固定其他参数,微调ID路由器,使用多标签交叉熵损失监督路由网络。
具体应用场景
- 个人故事创作:为个人故事生成定制化的视频,结合用户的文本提示和参考图像,生成具有个人特色的视频内容。
- 宣传视频:为产品或活动生成宣传视频,结合多个角色和场景,生成高质量、一致性的视频内容。
- 创意项目:为艺术和创意项目生成视频,结合多个参考图像和复杂的文本提示,生成具有创意和视觉冲击力的视频内容。
- 视频动画:为动画项目生成视频,结合多个角色和动作提示,生成连贯且一致的动画视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











