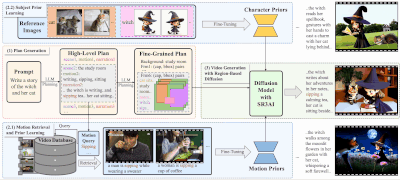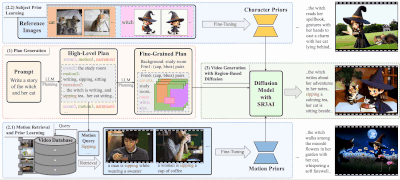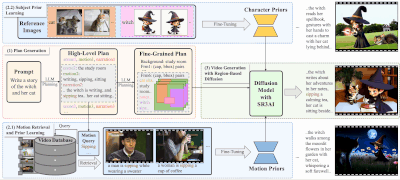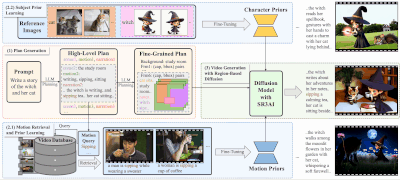
在图像编辑领域,用户常常需要执行诸如“将这张照片转换为赛博朋克风格”或“让图中的动物看起来像是在庆祝圣诞节”这样的复杂操作。这些任务不仅要求模型理解抽象指令,还需准确定位并修改图像中的特定区域。

然而,传统图像编辑方法在面对这类间接性、多对象、多步骤的复杂指令时往往表现不佳,例如:
- 难以解析语义模糊的描述
- 编辑区域定位不准确
- 编辑过程中丢失原始对象身份信息
为了解决这些问题,来自 加州大学伯克利分校、香港大学和 Adobe 的研究团队 提出了一个全新的解决方案:X-Planner —— 一种基于多模态大型语言模型(MLLM)的图像编辑任务规划系统。
核心功能
X-Planner 能够:
- 分解复杂指令
将复杂的自然语言指令拆解为多个简单子任务,例如:- “将这张照片转换为赛博朋克风格” → 分解为“改变树木纹理”、“添加宇宙飞船”等具体操作。
- 精确定位编辑区域
为每个子任务生成对应的 分割掩码(Segmentation Mask) 和 边界框(Bounding Box),确保编辑仅发生在目标区域。 - 动态选择编辑模型
根据任务类型(插入、替换、风格迁移等),自动匹配最适合的图像编辑模型。

技术亮点
✅ 多模态大语言模型驱动
X-Planner 利用 MLLM 强大的语言理解和视觉分析能力,实现对复杂指令的解析与编辑策略的制定。
✅ 自动化训练数据生成管道
为了训练 X-Planner,研究团队开发了一套三级自动化数据生成流程:
| 阶段 | 内容 |
|---|---|
| 第一级 | 使用 GPT-4o 模板生成结构化的“复杂指令-子指令对”,涵盖多对象、多步骤编辑任务,并标注对象锚点与编辑类型 |
| 第二级 | 基于 Grounded SAM 提取对象掩码,并根据编辑类型优化掩码质量 |
| 第三级 | 对“插入类”任务预训练 MLLM,使其能在无视觉证据的情况下预测合理的边界框 |
✅ 新基准测试集 COMPIE
团队还构建了一个专注于复杂指令编辑的新评估数据集 COMPIE,用于衡量模型对复杂指令的理解与执行能力。

工作原理详解
X-Planner 的完整工作流程如下:
- 指令分解
- 输入:用户提供的复杂自然语言指令
- 输出:一系列可执行的子任务(如插入、替换、风格变更)
- 区域定位
- 为每个子任务生成精确的图像区域标注(掩码 + 边界框)
- 示例:“在猫周围添加圣诞装饰” → 生成猫的掩码 + 装饰物应出现的边界框
- 模型选择
- 动态匹配最适合当前子任务的编辑模型(如风格迁移模型、图像插入模型)
- 迭代编辑
- 按顺序执行各子任务,最终输出符合复杂指令的编辑结果
测试结果与优势
✅ 简单指令测试(MagicBrush 基准)
- 显著提升 UltraEdit 等图像编辑模型的表现
- 在保持对象身份方面(L1 距离、CLIP 相似度)优于现有方法
✅ 复杂指令测试(COMPIE 基准)
- 通过分解指令 + 掩码引导,显著提高编辑模型对复杂指令的理解力
- 在 MLLM 文本-图像对齐(MLLMti)、图像相似度(MLLMim)等指标上表现优异
✅ 用户研究反馈
- 用户普遍认为 X-Planner 生成的图像:
- 更好地保留了原图身份特征
- 更贴合指令意图
- 整体质量更高

可视化效果展示
X-Planner 在多次运行中展现出良好的一致性与多样性:
- 对插入类任务(如添加独角兽、笔记本电脑等)能持续生成合理、语义一致的边界框
- 同时引入自然的变化(位置、角度不同),避免重复单调的输出
实际应用价值
X-Planner 的推出,为图像编辑带来了三大核心优势:
| 优势 | 描述 |
|---|---|
| 高效性 | 减少手动标注和调整的时间,提升编辑效率 |
| 可控性 | 提供明确的编辑范围控制,防止误操作 |
| 扩展性 | 支持多种编辑模型集成,适应多样化的图像处理需求 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











