在 RAG(Retrieval-Augmented Generation)系统中,信息检索是决定整体性能的关键环节。传统的单向量搜索(如基于 ElasticSearch 或 FAISS 的 MIPS)虽然速度快,但表达能力有限;而现代多向量模型(如 ColBERT)通过为每个 token 生成嵌入来捕捉更丰富的语义关系,显著提升了准确性,却带来了巨大的计算成本。
多向量检索的三大痛点:
- 嵌入数量激增:一个文档可能包含数百个向量;
- 复杂度高:使用 Chamfer 相似度等非线性匹配机制,计算开销远高于点积;
- 缺乏高效的亚线性搜索方法:传统 MIPS 算法难以直接应用于多向量场景。
这导致多向量检索效率大幅下降,严重限制了其在大规模实时系统中的落地。
解决方案:MUVERA —— 固定维度编码(FDE)
谷歌提出了一种创新性的解决方案——MUVERA(Multi-Vector Retrieval via Fixed-Dimension Embeddings),它通过将复杂的多向量相似性问题转换为高效的单向量最大内积搜索(MIPS),从而实现速度与精度的平衡。(来源)
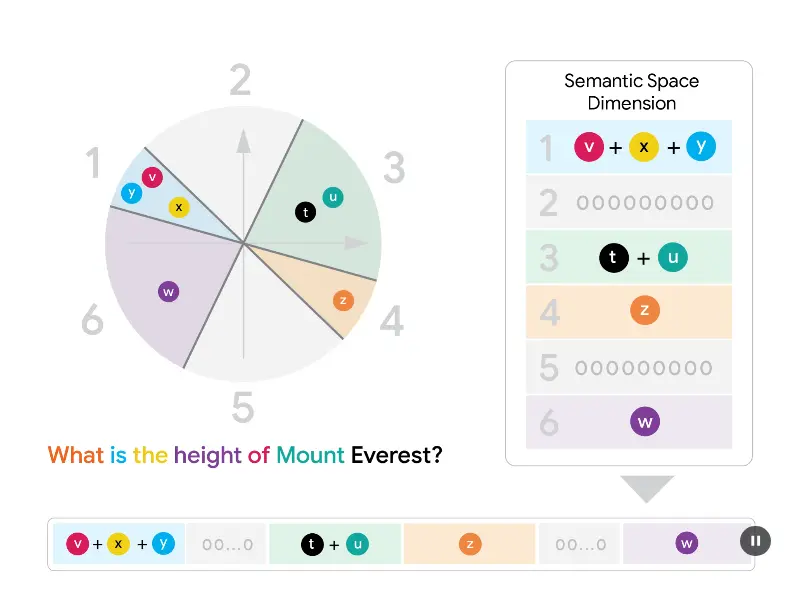
✅ 核心思想
- FDE(Fixed-Dimension Embedding):将多向量集合压缩为固定长度的单向量表示。
- 点积近似 Chamfer 相似度:两个 FDE 向量之间的点积近似于原始多向量集合之间的 Chamfer 相似度。
- 两阶段检索流程:
- 快速召回:使用标准 MIPS 搜索初步筛选候选文档;
- 重排序:用原始 Chamfer 相似度对候选进行精排。
这一过程不仅保留了多向量的高精度优势,还继承了单向量检索的速度优势。
技术亮点
| 特性 | 描述 |
|---|---|
| 🔓 无数据依赖变换 | FDE 编码不依赖训练数据,具有更强的数据分布鲁棒性和流式处理适应性。 |
| 📏 误差可控的近似保证 | 在指定误差范围内严格逼近 Chamfer 相似度,确保最终结果的可靠性。 |
| 🧩 理论支撑 | 借鉴概率树嵌入思想,采用随机分区策略构建映射函数,具备坚实的数学基础。 |
| 🚀 兼容现有索引结构 | 可无缝接入 FAISS、ANN 等高度优化的 MIPS 索引库,无需重构整个检索系统。 |
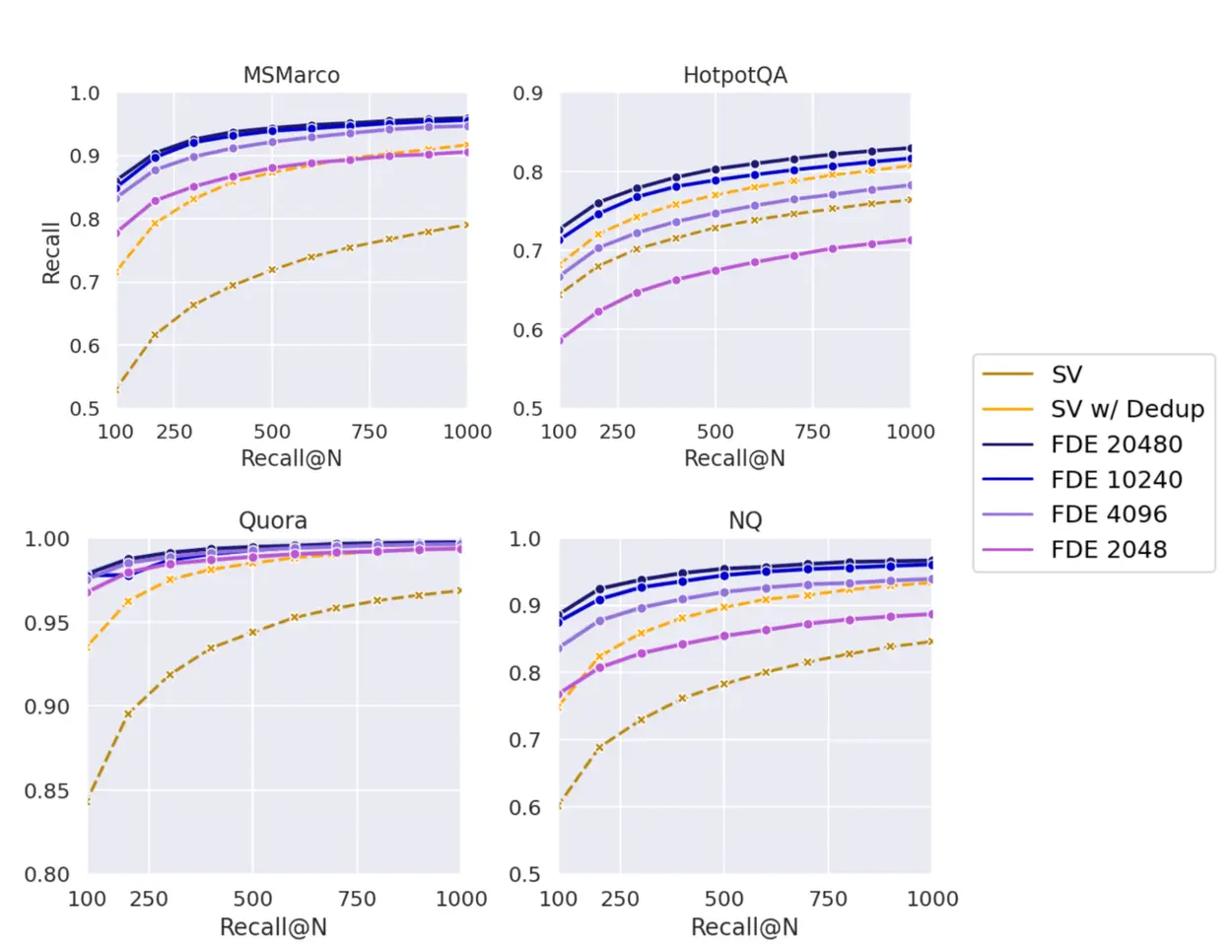
实验结果与优势
在 BEIR 基准测试中,MUVERA 表现出以下优势:
- 更高的召回率:相比传统单向量方法,在相同召回率下仅需检索 5~20 倍更少的候选文档。
- 更快的检索速度:利用成熟的 MIPS 技术栈,显著降低检索延迟。
- 优秀的压缩性能:FDE 支持产品量化压缩,内存占用减少 32 倍,且对检索质量影响极小。
这些结果表明,MUVERA 成功弥合了多向量准确性和单向量效率之间的鸿沟。
应用场景
MUVERA 非常适合需要在大规模语料库中实现高精度、低延迟检索的应用,包括但不限于:
- 搜索引擎中的语义匹配
- 推荐系统的个性化召回
- NLP 中的问答与对话理解
- 视频/图像检索中的细粒度匹配
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...