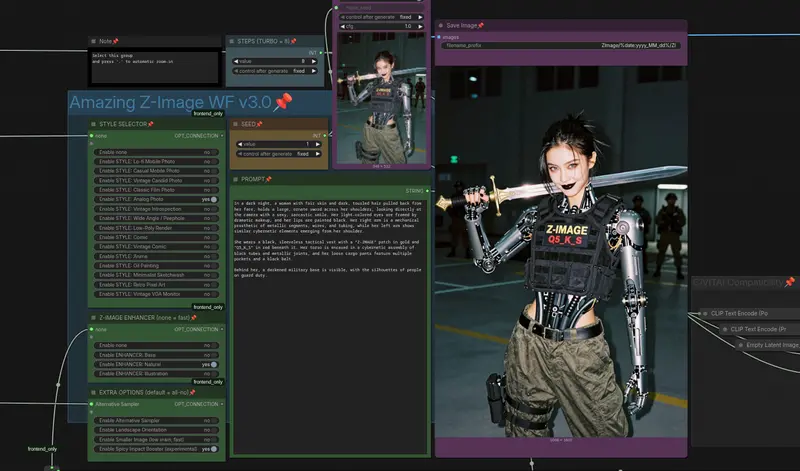
9月4日,Nunchaku 团队正式发布 v1.0.0 版本,标志着这一面向 4 位量化神经网络(SVDQuant) 的高性能推理引擎进入稳定可用阶段。
- GitHub:https://github.com/nunchaku-tech/nunchaku
- ComfyUI-nunchaku:https://github.com/nunchaku-tech/ComfyUI-nunchaku
- 插件下载:https://pan.quark.cn/s/b696a96e1bfa 提取码:ntjD
Nunchaku 专注于解决大模型在低显存设备上的部署难题,通过深度优化量化计算流程,在显著降低显存占用的同时,保持接近原始精度的推理速度。本次更新不仅完成核心架构升级,还首次正式支持 Qwen-Image 与 Qwen-Image-Edit 模型系列,为多模态应用提供了轻量化落地的新选择。
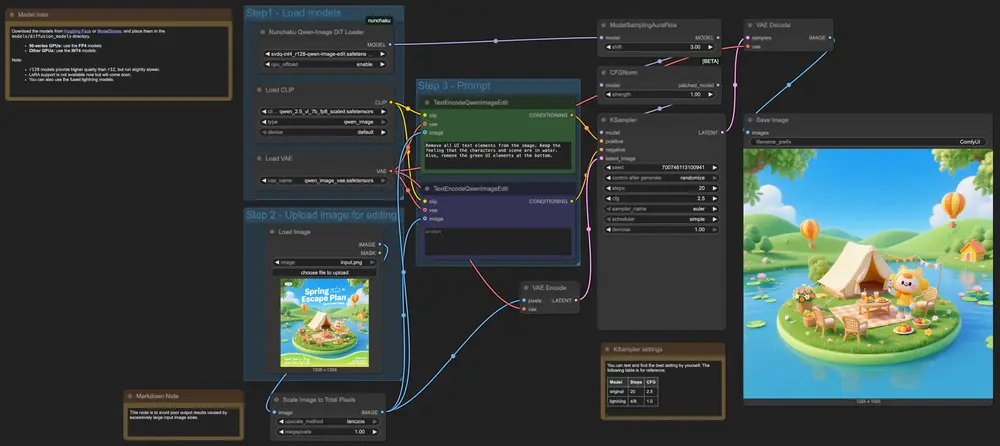
核心定位:为 SVDQuant 架构量身打造的推理引擎
Nunchaku 并非通用推理框架,而是专门为 SVDQuant(奇异值分解量化) 技术路径设计的专用引擎。其目标是:
- 最大化 4-bit 量化模型的运行效率
- 显著降低 Transformer 层显存占用
- 提供稳定、可集成的生产级接口
相比传统推理方案,Nunchaku 在处理高度压缩的视觉-语言模型时展现出更强的兼容性与性能优势。
v1.0.0 主要更新亮点
✅ 1. 后端重构:从 C 到 Python,提升兼容性与易用性
此前版本基于 C 语言实现核心模块,虽然性能优异但集成复杂。v1.0.0 完成了向 Python 原生后端 的迁移:
- 更易于与 PyTorch 生态集成
- 支持更广泛的硬件平台和运行环境
- 简化安装与调试流程,降低使用门槛
这一转变使 Nunchaku 更适合研究者和开发者快速实验与部署。
✅ 2. 支持异步 CPU 卸载,显存占用降至约 3 GiB
这是本次发布的最大亮点之一。
启用异步卸载功能后:
- Qwen-Image 扩散模型仅需约 3 GiB 显存
- 推理速度无明显损失
- 可在消费级显卡(如 RTX 3060/4060)上流畅运行
该技术通过智能调度机制,将部分中间状态临时卸载至内存,在需要时再异步加载回 GPU,实现了“低显存 + 高性能”的平衡。
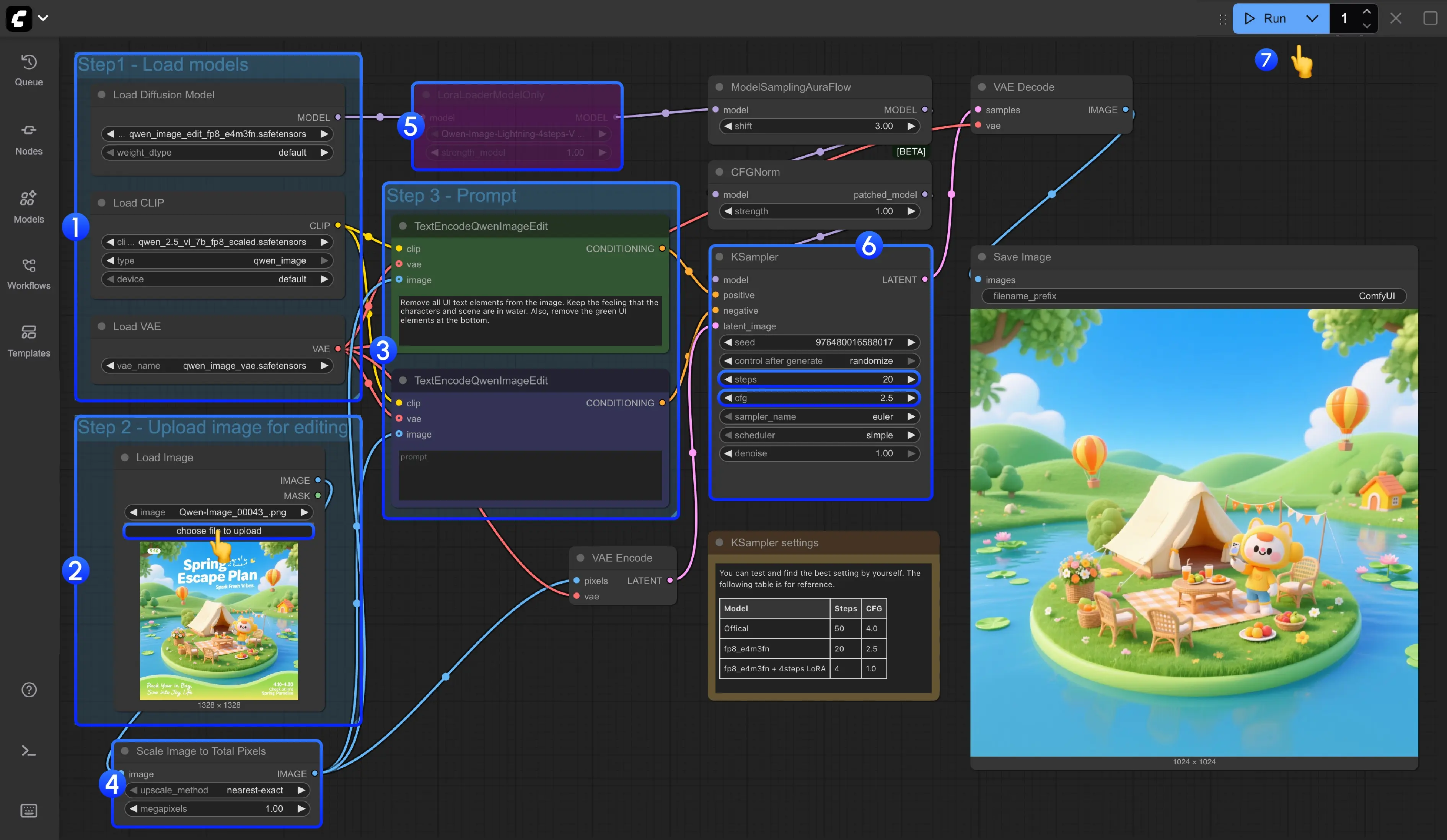
✅ 3. 正式支持 Qwen-Image 与 Qwen-Image-Edit
v1.0.0 开始原生支持通义实验室推出的两个关键多模态模型:
- Qwen-Image:图文理解与生成基础模型
- Qwen-Image-Edit:图像编辑专用模型
⚠️ 当前限制:暂不支持 LoRA 微调模型
尽管基础模型支持已完善,但目前 尚未支持 Qwen-Image 和 Qwen-Image-Edit 的 LoRA 模型。
这意味着:
- 用户无法直接加载社区微调的个性化Lora模型
- 图像编辑任务中的精细控制能力受限
- 实际应用场景(如定制化图像生成)仍有一定局限
团队表示将在后续版本中优先推进 LoRA 兼容性开发。
Nunchaku 安装方法
Nunchaku安装方法可参考《秒速出图!Nunchaku无损加速Flux生图,支持多LoRA和ControlNet》,根据自己的Python和PyTorch 版本选择适合自己的轮子文件。
下载轮子文件后,在 ComfyUI\python 目录下右键,选择“在终端中打开”,输入以下命令进行安装:
.\python.exe -m pip install 文件地址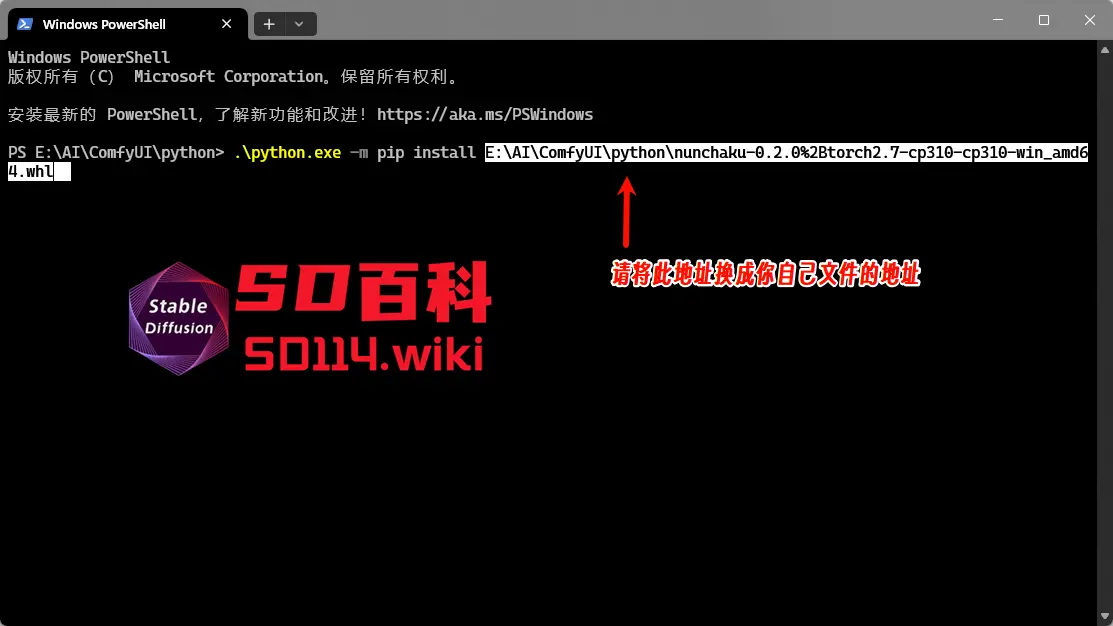
nunchaku-qwen-image
Nunchaku 量化的 Qwen-Image 版本,专为从文本提示生成高质量图像而设计,在复杂文本渲染方面取得了进步。它针对高效推理进行了优化,同时保持最小的性能损失。
- Hugging Face:https://huggingface.co/nunchaku-tech/nunchaku-qwen-image
- 魔塔:https://www.modelscope.cn/models/nunchaku-tech/nunchaku-qwen-image
模型文件
| 模型名称 | 量化方法 | 秩 | 步骤 | LoRA 强度 | 适用 GPU | 备注 |
|---|---|---|---|---|---|---|
| svdq-int4_r32-qwen-image.safetensors | SVDQuant INT4 | 32 | - | - | 非 Blackwell GPU(50 系列之前) | - |
| svdq-int4_r128-qwen-image.safetensors | SVDQuant INT4 | 128 | - | - | 非 Blackwell GPU(50 系列之前) | 质量更佳,但速度较慢 |
| svdq-int4_r32-qwen-image-lightningv1.0-4steps.safetensors | SVDQuant INT4 | 32 | 4 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-int4_r128-qwen-image-lightningv1.0-4steps.safetensors | SVDQuant INT4 | 128 | 4 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-int4_r32-qwen-image-lightningv1.1-8steps.safetensors | SVDQuant INT4 | 32 | 8 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors 生成 |
| svdq-int4_r128-qwen-image-lightningv1.1-8steps.safetensors | SVDQuant INT4 | 128 | 8 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors 生成 |
| svdq-fp4_r32-qwen-image.safetensors | SVDQuant NVFP4 | 32 | - | - | Blackwell GPU(50 系列) | - |
| svdq-fp4_r128-qwen-image.safetensors | SVDQuant NVFP4 | 128 | - | - | Blackwell GPU(50 系列) | 质量更佳,但速度较慢 |
| svdq-fp4_r32-qwen-image-lightningv1.0-4steps.safetensors | SVDQuant NVFP4 | 32 | 4 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-fp4_r128-qwen-image-lightningv1.0-4steps.safetensors | SVDQuant NVFP4 | 128 | 4 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-fp4_r32-qwen-image-lightningv1.1-8steps.safetensors | SVDQuant NVFP4 | 32 | 8 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors 生成 |
| svdq-fp4_r128-qwen-image-lightningv1.1-8steps.safetensors | SVDQuant NVFP4 | 128 | 8 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Lightning-8steps-V1.1-bf16.safetensors 生成 |
说明
- 量化方法:SVDQuant INT4 和 SVDQuant NVFP4 是两种不同的量化方法,分别适用于不同的 GPU 架构。
- 秩:表示模型的压缩程度,秩越高,模型质量越好,但速度可能较慢。
- 步骤:表示模型的推理步骤数,步骤数越多,模型的推理能力越强。
- LoRA 强度:表示模型融合时使用的 LoRA(Low-Rank Adaptation)强度。
- 适用 GPU:根据 GPU 架构的不同,选择合适的模型。
- 备注:对模型的生成方式或特点进行补充说明。
使用方法
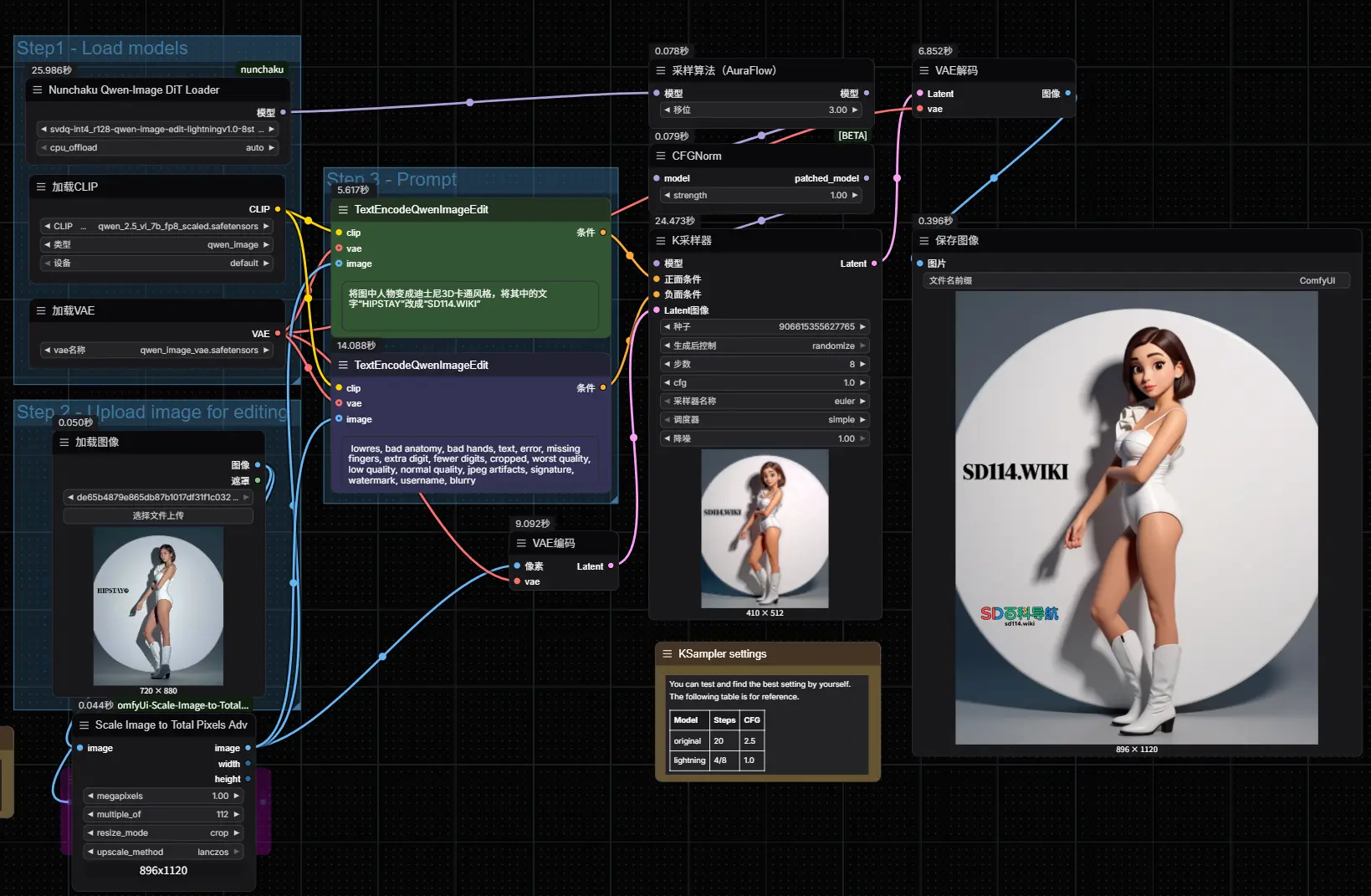
从custom_nodes\ComfyUI-nunchaku\example_workflows目录下,将nunchaku-qwen-image工作流拖入ComfyUI即可使用。
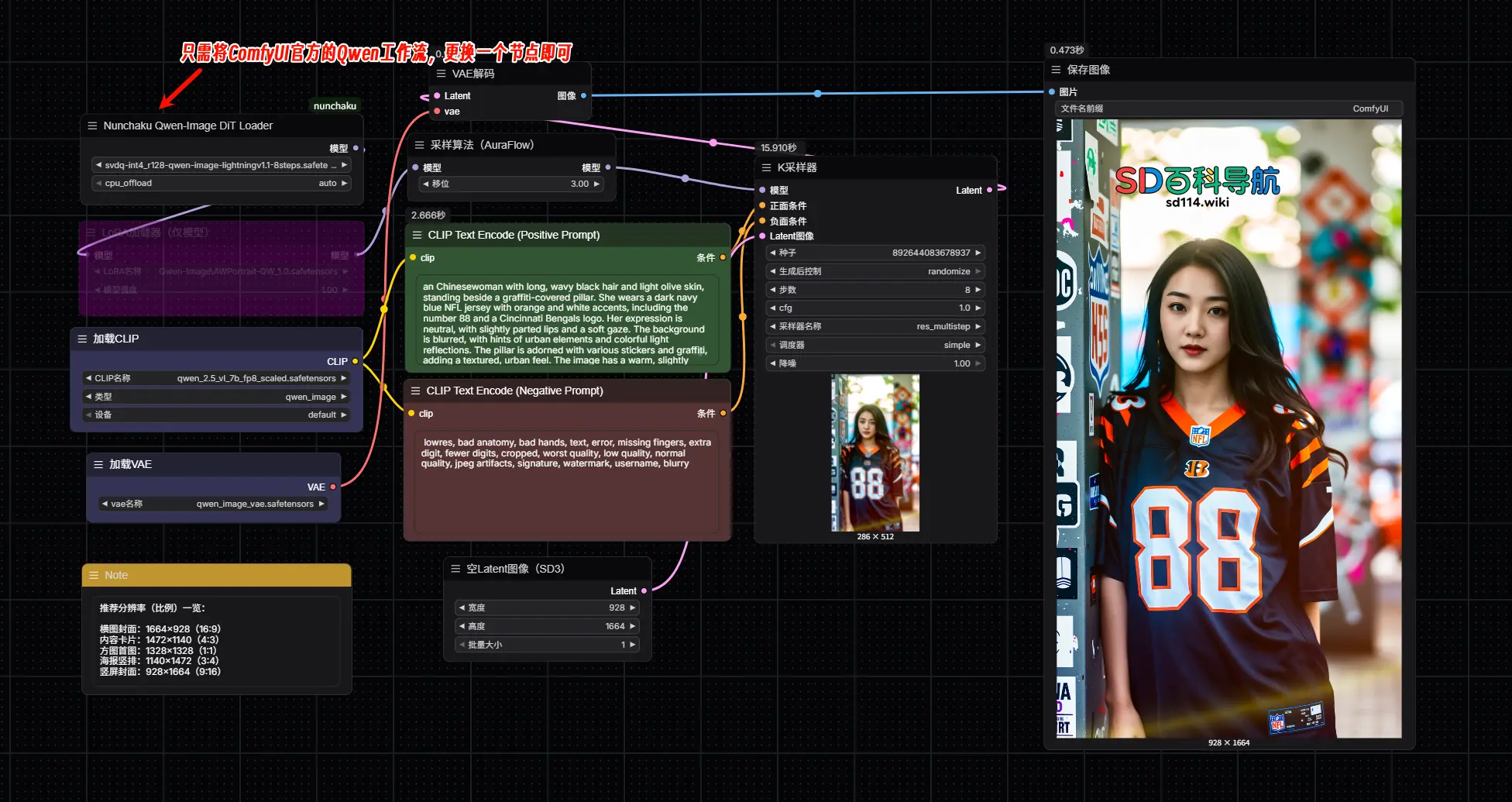
nunchaku-qwen-image-edit
Qwen-Image-Edit的 Nunchaku 量化版本。它针对高效的推理进行了优化,同时保持了最小的性能损失。
- Hugging Face:https://huggingface.co/nunchaku-tech/nunchaku-qwen-image-edit
- 魔塔:https://modelscope.cn/models/nunchaku-tech/nunchaku-qwen-image-edit
模型文件
| 模型名称 | 量化方法 | 秩 | 步骤 | LoRA 强度 | 适用 GPU | 备注 |
|---|---|---|---|---|---|---|
| svdq-int4_r32-qwen-image-edit.safetensors | SVDQuant INT4 | 32 | - | - | 非 Blackwell GPU(50 系列之前) | - |
| svdq-int4_r128-qwen-image-edit.safetensors | SVDQuant INT4 | 128 | - | - | 非 Blackwell GPU(50 系列之前) | 质量更好,但速度较慢 |
| svdq-int4_r32-qwen-image-edit-lightningv1.0-4steps.safetensors | SVDQuant INT4 | 32 | 4 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Edit-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-int4_r128-qwen-image-edit-lightningv1.0-4steps.safetensors | SVDQuant INT4 | 128 | 4 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Edit-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-int4_r32-qwen-image-edit-lightningv1.0-8steps.safetensors | SVDQuant INT4 | 32 | 8 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Edit-Lightning-8steps-V1.0-bf16.safetensors 生成 |
| svdq-int4_r128-qwen-image-edit-lightningv1.0-8steps.safetensors | SVDQuant INT4 | 128 | 8 | 1.0 | 非 Blackwell GPU(50 系列之前) | 融合 Qwen-Image-Edit-Lightning-8steps-V1.0-bf16.safetensors 生成 |
| svdq-fp4_r32-qwen-image-edit.safetensors | SVDQuant NVFP4 | 32 | - | - | Blackwell GPU(50 系列) | - |
| svdq-fp4_r128-qwen-image-edit.safetensors | SVDQuant NVFP4 | 128 | - | - | Blackwell GPU(50 系列) | 质量更好,但速度较慢 |
| svdq-fp4_r32-qwen-image-edit-lightningv1.0-4steps.safetensors | SVDQuant NVFP4 | 32 | 4 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Edit-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-fp4_r128-qwen-image-edit-lightningv1.0-4steps.safetensors | SVDQuant NVFP4 | 128 | 4 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Edit-Lightning-4steps-V1.0-bf16.safetensors 生成 |
| svdq-fp4_r32-qwen-image-edit-lightningv1.0-8steps.safetensors | SVDQuant NVFP4 | 32 | 8 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Edit-Lightning-8steps-V1.0-bf16.safetensors 生成 |
| svdq-fp4_r128-qwen-image-edit-lightningv1.0-8steps.safetensors | SVDQuant NVFP4 | 128 | 8 | 1.0 | Blackwell GPU(50 系列) | 融合 Qwen-Image-Edit-Lightning-8steps-V1.0-bf16.safetensors 生成 |
说明
- 量化方法:SVDQuant INT4 和 SVDQuant NVFP4 是两种不同的量化方法,分别适用于不同的 GPU 架构。
- 秩:表示模型的压缩程度,秩越高,模型质量越好,但速度可能较慢。
- 步骤:表示模型的推理步骤数,步骤数越多,模型的推理能力越强。
- LoRA 强度:表示模型融合时使用的 LoRA(Low-Rank Adaptation)强度。
- 适用 GPU:根据 GPU 架构的不同,选择合适的模型。
- 备注:对模型的生成方式或特点进行补充说明。
使用方法
从custom_nodes\ComfyUI-nunchaku\example_workflows目录下,将nunchaku-qwen-image-edit工作流拖入ComfyUI即可使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











