ComfyUI已全面适配ACE-Step 1.5!这款兼具商用级质量、极速生成、低硬件门槛的开源音乐基础模型,落地可视化工作流后进一步降低使用门槛,让普通用户在消费级硬件上,就能轻松实现10秒生成完整歌曲、自定义风格微调的AI音乐创作,还支持50+种语言精准响应,成为ComfyUI生态中首个兼具高性价比与专业能力的音乐生成工具。
- 模型:https://huggingface.co/Comfy-Org/ace_step_1.5_ComfyUI_files
- 网盘下载:https://pan.quark.cn/s/4047fa11d656?pwd=aya2
核心亮点:ComfyUI端的商用级音乐创作能力
落地ComfyUI后,ACE-Step 1.5依旧保留核心优势,且适配可视化操作的使用习惯,从质量、速度、硬件、兼容性多维度拉满体验,普通用户无需代码即可解锁专业音乐生成:
- 商用级质量,连贯性评分4.72:在标准音乐评估指标上超越多数商业模型,歌曲旋律、编曲、结构的连贯性评分达4.72,生成内容可直接用于商业场景,无版权风险;
- 极致生成速度,全硬件适配:高性能显卡端极速出片——RTX 5090上1秒生成4分钟完整歌曲,消费级显卡RTX 3090也能做到不到10秒出歌,大幅提升创作效率;
- 超低显存要求,消费级硬件友好:本地运行仅需少于4GB显存,普通家用电脑、入门级显卡均可流畅运行,无需高端配置,真正实现全民AI音乐创作;
- 50+语言精准支持,多语种创作无压力:严格遵循50多种语言的提示词要求,对英语、中文、日韩语、西法德等主流语言做专项优化,用母语描述创作需求即可精准响应;
- 可视化操作,零代码上手:适配ComfyUI的可视化工作流,无需编写代码,通过拖拽节点、填写参数即可完成音乐生成,新手也能快速上手。
核心能力:不止于生成,更懂专业音乐创作
ACE-Step 1.5并非简单的“文本转音频”工具,而是融合了思维链规划、LoRA轻量微调、专业结构控制的全流程AI音乐创作系统,落地ComfyUI后,这些能力通过可视化参数即可调节,更贴合创作者的操作习惯。
1. 思维链规划:从简单提示到完整歌曲蓝图
模型内置的语言模型(LM)充当“全能规划师”,通过思维链推理,将用户的简单文本提示(如“中文流行,温柔女声,钢琴伴奏,副歌抒情”),自动转化为包含歌曲结构、配器、节奏、元数据的完整创作蓝图,还能同步合成歌词、风格描述,指导后续音频生成。
这种规划能力让模型能轻松驾驭从短音乐循环到10分钟长作品的全尺度创作,解决了传统AI音乐生成“长篇作品结构混乱、连贯性差”的痛点。
2. LoRA轻量微调:本地定制专属音乐风格,数据绝对安全
支持ComfyUI端的LoRA轻量级个性化微调,无需海量训练数据,仅需几首甚至几十首个人歌曲,就能训练出捕捉专属风格的LoRA模型,精准还原个人创作的音色、编曲特点。
更重要的是,所有微调过程本地完成,无需上传数据到云端,既保证了创作风格的唯一性,又彻底避免数据泄露,创作者完全拥有自己的LoRA模型。
3. 专业结构控制:精准定义歌曲框架,创作更可控
在ComfyUI工作流中,可通过简单参数设置实现歌曲结构的精细化控制,让AI生成更贴合专业创作需求:
- 用
[verse](主歌)、[chorus](副歌)、[bridge](桥段)等标签,直接定义歌曲的段落结构; - 通过风格标签精准指定流派、乐器、情绪、节奏(如
摇滚,电吉他,120bpm,充满活力),标签越具体,生成效果越贴合预期; - 支持批量生成(设置
batch_size为8/16),可从多个样本中挑选最佳结果,解决模型输出偶尔不稳定的问题。
技术内核:四大架构创新,支撑高性价比创作
ACE-Step 1.5能在低硬件门槛下实现商用级质量与极速生成,核心源于四大独创的架构与技术创新,也是其区别于其他音乐生成模型的核心竞争力:
- 混合LM + DiT架构:语言模型(LM)专门负责歌曲结构规划、需求解析,扩散变换器(DiT)专注音频合成,分工协作让“控制精准度”与“生成质量”双重拉满;
- 分布匹配蒸馏(DMD2):借鉴Z-Image的DMD2技术,在保证音乐质量的同时,实现推理速度的大幅提升,让A100上2秒生成完整歌曲成为可能;
- 内在强化学习:无需外部奖励模型或人类偏好标注,仅通过模型内部机制实现LM规划与DiT生成的精准对齐,消除外部偏见,让生成结果既贴合提示词,又保留创作多样性;
- 自学习音频分词器:音频分词器与DiT模型同步训练,能自主学习音频特征,大幅缩小“音频生成”与“特征分词”之间的差距,提升生成音频的保真度与自然度。
隐藏功能:即将解锁,让音乐创作更灵活
目前ACE-Step 1.5在ComfyUI中暂未开放部分进阶功能,官方表示这些功能将逐步解锁,也期待社区开发者探索适配方案,解锁更多创作可能:
- 翻唱生成:输入任意歌曲,搭配新的提示词和歌词,模型就能用完全不同的风格重新演绎,实现“一首歌曲,百种曲风”,比如将流行歌改编为古风、摇滚版本;
- 音乐重绘:针对生成歌曲中不满意的片段,无需重新生成整首歌,仅选择该片段进行局部重绘,模型会将重绘后的内容无缝衔接回原曲,保持整体结构和风格不变,大幅提升创作迭代效率。
ComfyUI端快速开始:四步解锁,零代码生成专属音乐
适配ComfyUI后,ACE-Step 1.5的使用流程极致简化,无论是桌面版还是本地部署的ComfyUI,只需四步即可完成音乐生成,新手也能轻松操作:
步骤1:更新ComfyUI
将你的ComfyUI升级到最新版本,保证与ACE-Step 1.5工作流的兼容性;
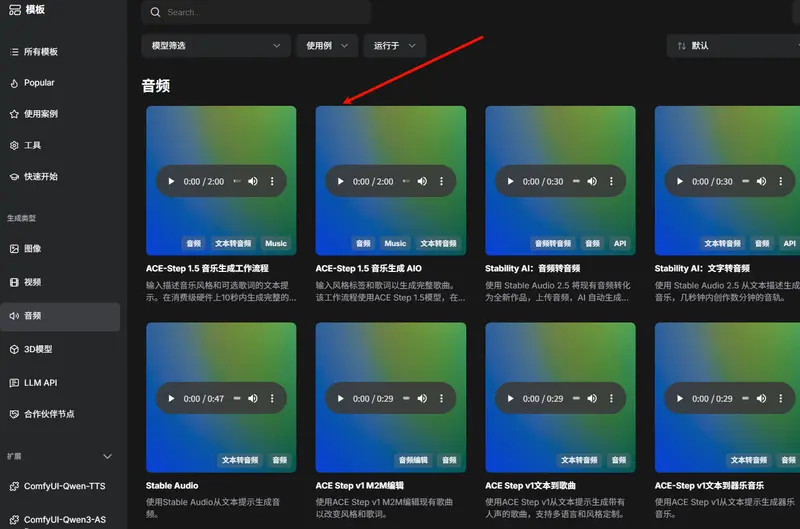
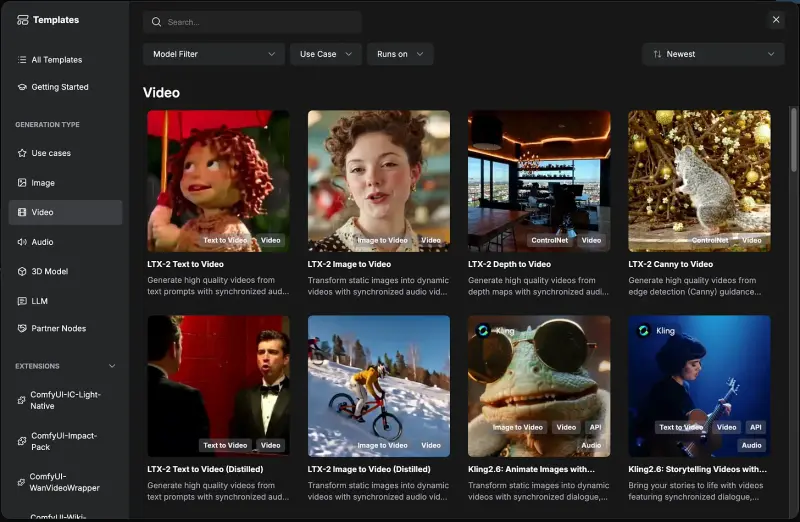
步骤2:选择专属音乐工作流
打开ComfyUI,进入模板库 → 音频分类,直接选择ACE-Step 1.5官方工作流,一键加载;
步骤3:下载模型
按照工作流内的提示,下载模型权重,放入指定模型目录;
步骤4:设置参数,运行生成
在工作流中填写风格标签、歌词(可按专业结构标注段落),按需调整歌曲时长、批量生成数量等参数,点击运行,即可生成专属音乐。
PS:启动ComfyUI时,加速方案不要用sage-attention,那样会导致生成歌曲时没有人声
参数项详细解析
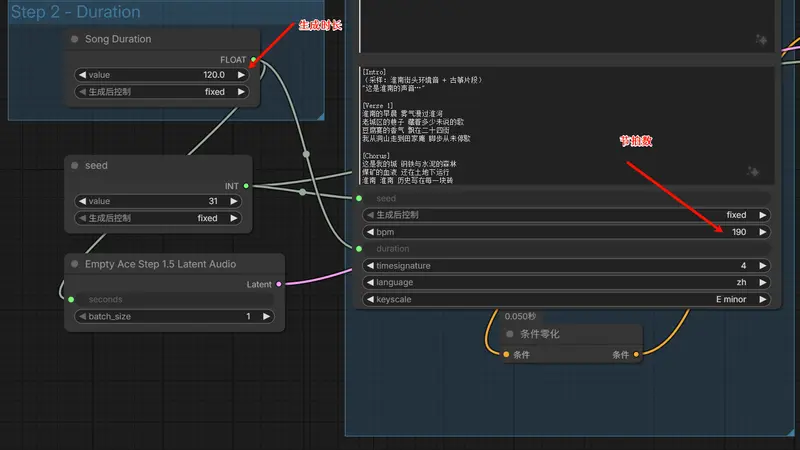
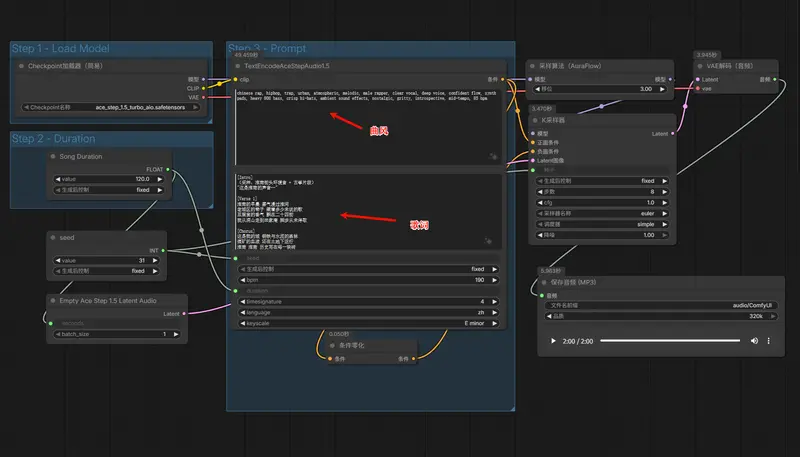
bpm (Beats Per Minute)
- 含义: 每分钟节拍数,即音乐的速度。
- 设置: 截图中是
190。 - 说唱建议: 对于说唱,190 BPM 通常被视为 Trap 风格的“双倍速(Double Time)”,实际听感约 95 BPM。这非常适合快嘴或充满能量的律动。如果想要怀旧慵懒的 Boom Bap 风格,建议调至
90-95。
timesignature (拍号)
- 含义: 音乐的节奏框架。
- 设置:
4代表常见的 4/4 拍(强、弱、次强、弱)。 - 说唱建议: 绝大多数说唱和流行歌都是 4/4 拍,保持默认即可。
keyscale (调式/音阶)
- 含义: 决定歌曲的情绪基调。
- 设置:
E minor(E 小调)。 - 说唱建议: * Minor (小调):通常听起来比较忧郁、酷、严肃或感伤,非常适合写实的城市说唱。
- Major (大调):听起来更积极、明亮。如果你想表现淮南未来的辉煌,可以换成
E major。
ComfyUI工作流实用小贴士:这些技巧让生成效果更优
掌握这些小技巧,能大幅提升ACE-Step 1.5在ComfyUI中的生成效果,让AI创作更贴合你的预期:
- 风格标签要具体:尽量包含流派、乐器、情绪、节奏、人声风格,例:
中文民谣,木吉他,轻柔女声,治愈,80bpm,吉他扫弦; - 歌词标注段落结构:用
[verse1]、[chorus]、[verse2]、[bridge]等标签划分歌词,模型会按专业歌曲结构生成,避免段落混乱; - 时长从90-120秒开始:新手建议先从90-120秒的歌曲开始尝试,生成结果的连贯性更优;若需生成180秒以上的长歌曲,可分多个批次生成后拼接;
- 开启批量生成:将
batch_size设置为8或16,一次生成多个样本,再从中挑选最佳结果,弥补模型偶尔输出不稳定的问题; - 结合LoRA微调:若有专属风格需求,可先本地训练LoRA模型,再在工作流中加载,生成贴合个人风格的音乐。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...