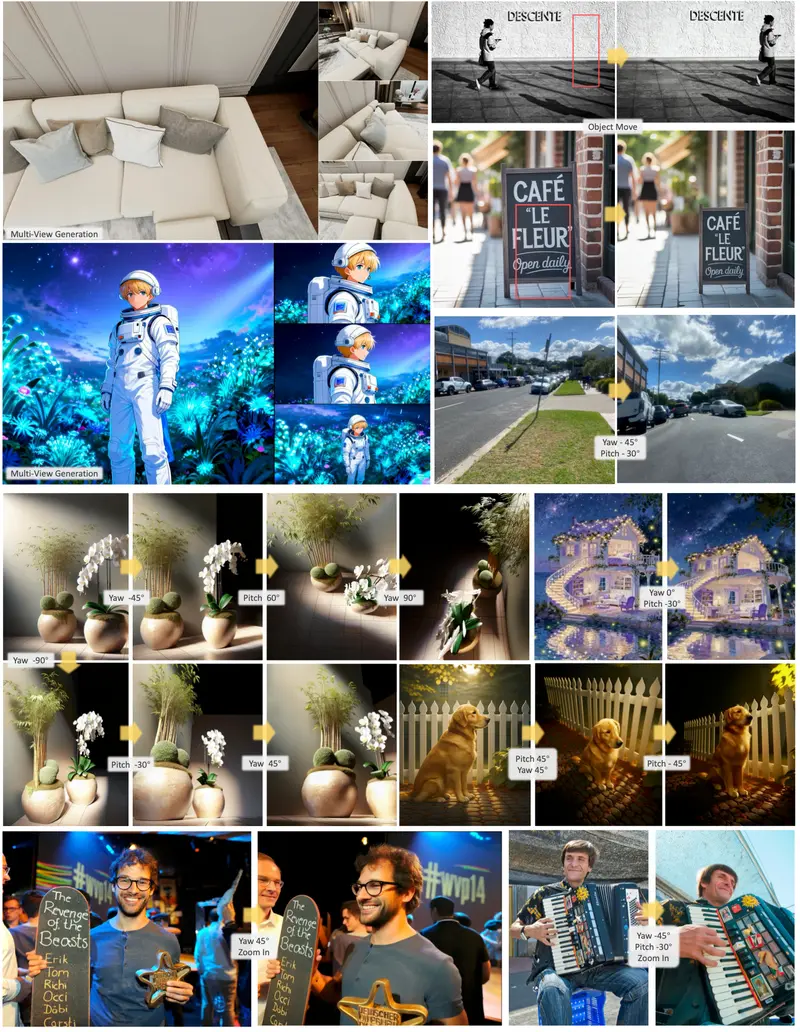
京东今日正式发布 JoyAI-Image,这是一款集图像理解、文生图(T2I)及指令引导编辑于一体的统一多模态基础模型。不同于传统模型将理解与生成割裂处理,JoyAI-Image 的核心理念是构建“理解 - 生成 - 编辑”的闭环协作,通过双向增强机制,真正唤醒了 AI 在视觉领域的空间智能(Spatial Intelligence)。
- GitHub:https://github.com/jd-opensource/JoyAI-Image
- 模型:https://huggingface.co/collections/jdopensource/joyai-image
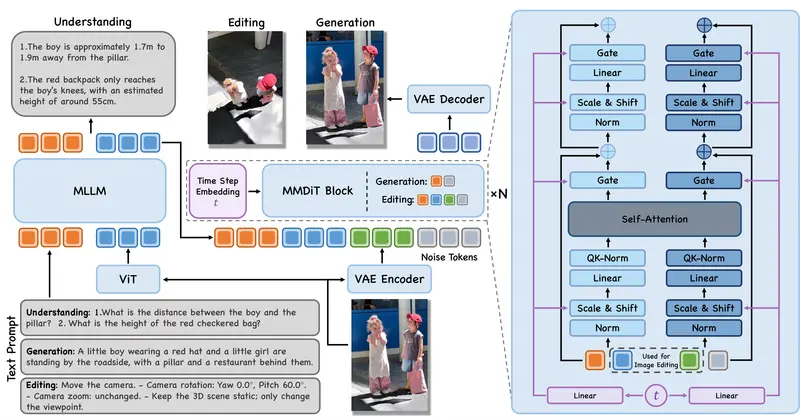
该模型系列由一个 8B 参数的多模态大语言模型 (MLLM) 和一个 16B 参数的多模态扩散变换器 (MMDiT) 强强联合而成,旨在解决当前 AI 绘图在复杂空间推理、长文本渲染及精确可控编辑上的痛点。
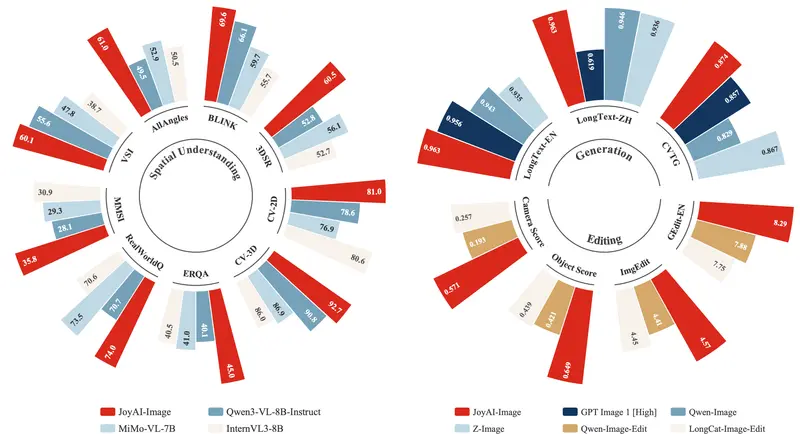
核心突破:理解与生成的双向飞轮
JoyAI-Image 的最大创新在于打破了单向的任务流,建立了闭环协作机制:
- 理解赋能生成:强大的空间理解能力(场景解析、关系定位、指令分解)让生成和编辑更加精准可控,不再出现“指东打西”的错误。
- 生成反哺理解:通过生成视角变化、物体旋转等变换,为空间推理提供互补的视觉证据,消除复杂空间关系的歧义。
“更强的理解带来更精准的生成,而多样的生成又验证并增强了理解。”
模型家族全景
JoyAI-Image 提供了一套完整的模型矩阵,覆盖从理解到创作的全流程:
| 模型名称 | 核心任务 | 关键能力 | 状态 |
|---|---|---|---|
| JoyAI-Image-Und | 多模态理解 | 高保真空间推理、编辑感知分析、复杂场景解析 | 🟢 已发布 |
| JoyAI-Image-Edit | 图像编辑 | 指令引导的精确空间操作、局部重绘、物体移除/替换 | 🟢 已发布 |
| JoyAI-Image-Edit-Plus | 多图像编辑 | 跨图像合成、多图一致性保持、联合操作 | 🟡 即将发布 |
| JoyAI-Image | 文生图 (T2I) | 高质量生成、多视图一致性、长文本排版 | 🟡 即将发布 |
四大核心亮点
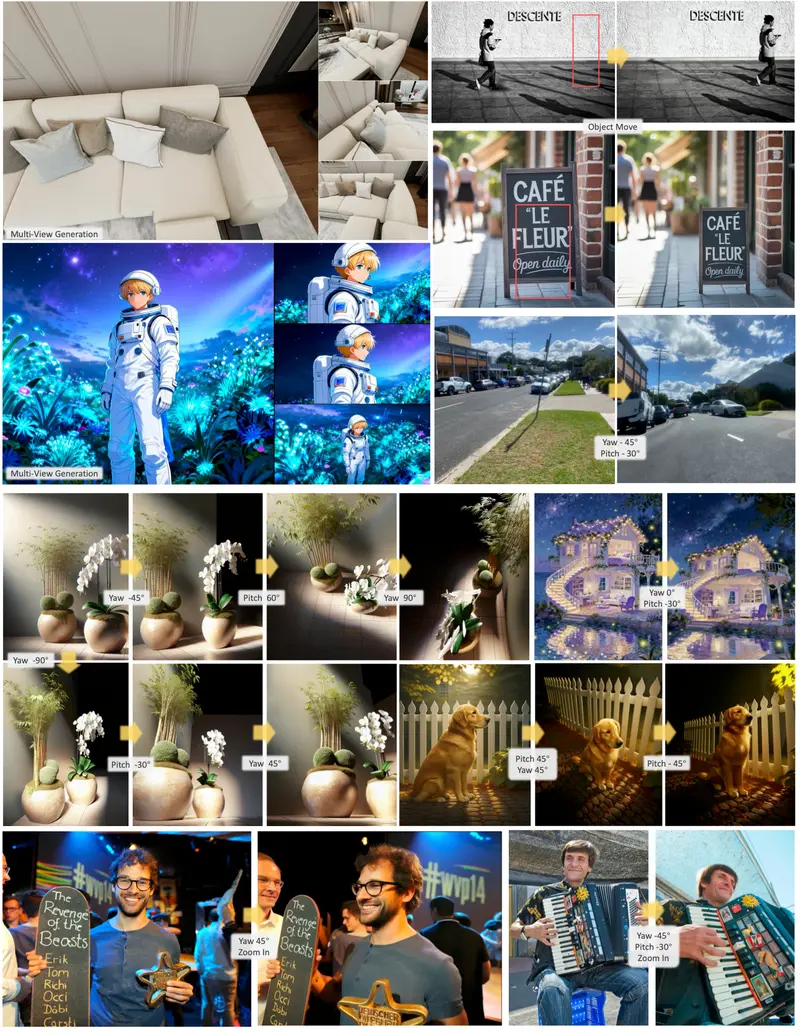
1. 唤醒的空间智能 (Awakened Spatial Intelligence)
- 几何感知:能够精准理解物体的三维结构、相对位置和遮挡关系。
- 视角控制:支持基于指令的相机运动(如“绕物体旋转 30 度”、“从俯视变为仰视”),生成的新视角符合透视规律,无畸变。
- 推理增强:通过生成诊断性的新视角(如物体背面),辅助解决复杂的空间推理问题(如“这个物体后面有什么?”)。

2. 极致的长文本渲染能力
针对 AI 绘图“怕文字”的顽疾,JoyAI-Image 进行了专项优化:
- 复杂排版:完美支持多格漫画、密集多行文本、多语言混排。
- 长格式布局:能处理海报、宣传单等长篇幅内容的整体布局。
- 风格多样:无论是印刷体、手写体还是艺术字,均能清晰呈现,无乱码或伪文现象。

3. 高保真可控编辑
- 精确指向:基于强大的理解能力,能准确识别“左边穿红衣服的人”、“桌子上的第二个苹果”等复杂指代。
- 结构保持:在编辑局部(如换衣服、改颜色)时,严格保持背景光影、物体结构和透视关系不变。
- 指令分解:自动将复杂指令(“把夏天的公园变成冬天,并加上圣诞树”)分解为多个可执行的子步骤。
4. 统一的多模态架构
- 共享接口:理解模型 (MLLM) 与生成模型 (MMDiT) 通过统一接口交互,无需繁琐的格式转换。
- 端到端优化:采用多阶段优化策略,利用空间理解数据、长文本数据和编辑数据进行联合训练,确保各模块能力协同进化。
应用场景演示
空间推理与编辑
- 任务:“把这个杯子顺时针旋转 90 度,并展示它的背面。”
- 效果:JoyAI-Image-Edit 不仅旋转了杯子,还合成了符合物理规律的背面细节(如把手的位置、标签的反面),消除了空间歧义。
长文本海报生成
- 任务:“生成一张春节促销海报,标题‘新春大吉’,包含五句不同的祝福语和产品价格列表。”
- 效果:文字清晰可读,排版美观,无错别字,完美还原设计意图。
多视图一致性创作
- 任务:“生成同一个角色在客厅、厨房和卧室的三个不同视角画面。”
- 效果:角色长相、衣着在三张图中保持高度一致,场景透视准确,适合漫画或故事板创作。
复杂指令编辑
- 任务:“把照片里那只正在睡觉的猫换成一只正在玩毛线球的狗,保持光影不变。”
- 效果:精准定位目标,替换自然,光影融合完美,无违和感。
技术架构简析
- 双引擎驱动:
- 8B MLLM (大脑):负责深度理解图像内容、解析复杂指令、规划编辑步骤。
- 16B MMDiT (双手):负责执行高质量的像素级生成与编辑,确保视觉逼真度。
- 数据飞轮:
- 构建了包含空间理解、长文本渲染、精细编辑的大规模高质量数据集。
- 采用多阶段训练策略,逐步提升模型在单一任务及跨任务协作上的表现。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...