
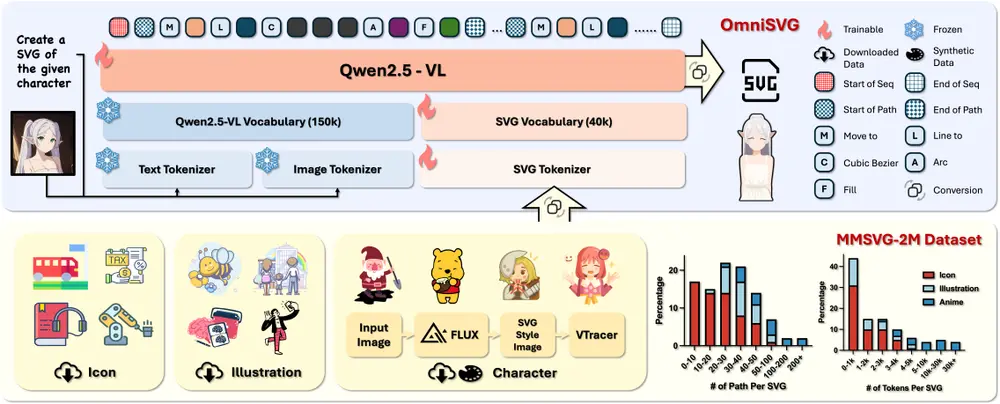
复旦大学和阶跃星辰的研究人员推出基于视觉语言模型(VLMs)的端到端多模态 SVG 生成框架OmniSVG,能够生成从简单图标到复杂动漫角色的高质量 SVG 图形,支持文本到 SVG、图像到 SVG 以及角色参考到 SVG 。
- 项目主页:https://omnisvg.github.io
- GitHub:https://github.com/OmniSVG/OmniSVG
- 模型:https://huggingface.co/OmniSVG/OmniSVG
- Demo:https://huggingface.co/spaces/OmniSVG/OmniSVG-3B
例如,OmniSVG 可以根据文本描述“一个穿着绿色和黄色蘑菇帽、红色斗篷的可爱卡通角色”生成相应的 SVG 图形,或者将一张图片转换为 SVG 格式,甚至可以根据角色参考图像生成新的 SVG 图形。这些功能展示了 OmniSVG 在不同生成模态下的多样性和灵活性。

主要功能
- 多模态 SVG 生成:OmniSVG 支持从文本到 SVG(Text-to-SVG)、从图像到 SVG(Image-to-SVG)以及基于角色参考的 SVG 生成(Character-Reference SVG)等多种生成方式。
- 高质量 SVG 输出:生成的 SVG 图形具有高视觉保真度和语义一致性,适用于多种设计领域。
- 复杂 SVG 生成:OmniSVG 能够处理复杂的 SVG 结构,生成包含数千个路径的高质量 SVG 图形。
- 编辑性:生成的 SVG 图形保持了 SVG 的可编辑性,便于后续修改和调整。
主要特点
- 统一框架:OmniSVG 是首个利用预训练 VLMs 进行端到端多模态复杂 SVG 生成的统一框架。
- SVG 参数化:通过将 SVG 命令和坐标参数化为离散标记,OmniSVG 分离了结构逻辑与低级几何信息,提高了训练效率并保持了复杂 SVG 结构的表达能力。
- 大规模数据集:论文引入了 MMSVG-2M,一个包含 200 万个丰富注释的 SVG 资产的多模态数据集,以及标准化的评估协议 MMSVG-Bench,为未来研究提供了全面的资源。
- 高效生成:OmniSVG 在生成复杂 SVG 时表现出色,生成时间显著优于传统优化方法。
工作原理
- SVG 参数化:OmniSVG 将 SVG 命令和坐标参数化为离散标记,通过简化 SVG 命令(如“Move To”、“Line To”、“Cubic Bézier”等)和颜色属性,将 SVG 图形表示为一个统一的标记序列。
- 模型架构:OmniSVG 基于预训练的 VLMs(如 Qwen2.5-VL),通过将文本和图像输入编码为前缀标记,并将 SVG 命令编码为序列,输入到解码器语言模型中进行生成。
- 训练目标:使用下一个标记预测损失进行训练,使模型能够根据前缀标记生成新的 SVG 标记。
- 多模态指令跟随:OmniSVG 能够处理多种模态的输入,包括文本描述、图像和角色参考图像,生成与输入指令高度一致的 SVG 图形。
应用场景
- 图形设计:OmniSVG 可以用于生成高质量的图标、插图和动漫角色,适用于 UI/UX 设计、平面设计和动画制作等领域。
- 内容创作:根据文本描述生成 SVG 图形,为内容创作者提供快速的图形生成工具,提高创作效率。
- 数据可视化:将数据或图像转换为 SVG 格式,便于在网页或其他应用程序中进行交互式可视化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











