在OpenAI旗下GPT‑4o凭借原生生成及编辑图像功能,火爆网络后,大家都在期待有相对应的开源模型推出。而将视觉和语言任务高效整合一直是研究的热点。华中科技大学、字节跳动和香港大学的研究人员推出了新型多模态生成模型 Liquid。该模型通过将图像和文本统一到一个共享的特征空间中,使大语言模型(LLMs)能够同时处理视觉理解和生成任务,为多模态 AI 的发展提供了新的思路。
- 项目主页:https://foundationvision.github.io/Liquid
- GitHub:https://github.com/FoundationVision/Liquid
- 模型:https://huggingface.co/Junfeng5/Liquid_V1_7B
- Demo:https://huggingface.co/spaces/Junfeng5/Liquid_demo
什么是 Liquid?
Liquid 是一种基于自回归生成范式的多模态模型,它通过将图像编码为离散的令牌,并与文本令牌一起在共享的特征空间中进行学习和生成,实现了视觉和语言任务的无缝整合。
不同于以往的多模态大语言模型(MLLM),Liquid 使用单一的大语言模型(LLM)实现了这种整合,无需依赖 CLIP 等外部预训练视觉嵌入。Liquid 探索了这种多模态混合模型的规模定律,并发现了理解与生成任务之间相互促进的现象。
变体:Liquid 提供六种规模——参数量分别为 0.5B、1B、2B、7B、9B、32B(来自多模态家族)的预训练变体,以及 7B(来自 GEMMA)的指令微调变体。 输入:模型接受文本和图像输入。 输出:模型生成文本或生成图像。 模型架构:Liquid 是一种基于现有大语言模型扩展的自回归模型,采用 transformer 架构。
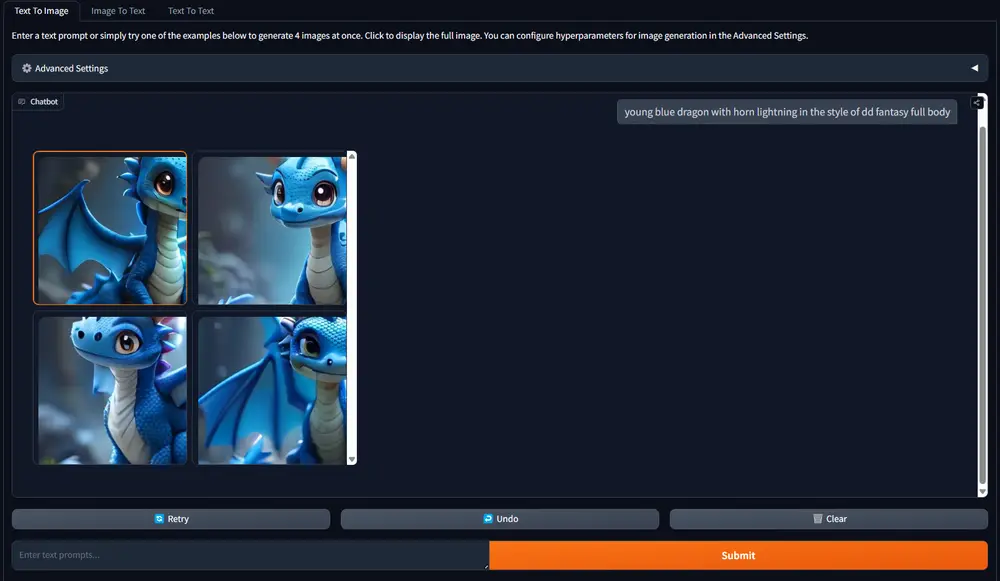
主要功能
视觉生成:根据文本提示生成高质量的图像。例如,输入“一个阳光明媚的海滩,有蓝色的海水、金色的沙滩和几棵棕榈树”,模型会生成一张符合描述的高质量图像。 视觉理解:能够理解和回答与图像相关的问题。例如,用户可以上传一张图片并询问“图中的人物在做什么?” 多模态融合:将视觉和语言任务统一在一个模型中,支持同时进行文本生成和图像生成。 可扩展性:基于现有的大型语言模型(LLMs),通过少量的高质量数据进行继续训练,实现视觉生成和理解能力的提升。

主要特点
统一的令牌空间:通过将图像和文本编码为离散的令牌,使两者共享相同的词汇表和嵌入空间。 无需外部预训练模型:不依赖于外部的视觉嵌入(如 CLIP)或扩散模型,直接在统一的空间中进行训练和生成。 高效的训练框架:利用现有的 LLMs 作为基础,通过继续训练的方式,显著降低了训练成本。 强大的多模态能力:在视觉生成和语言任务上均表现出色,同时在多模态任务中实现了相互增强。
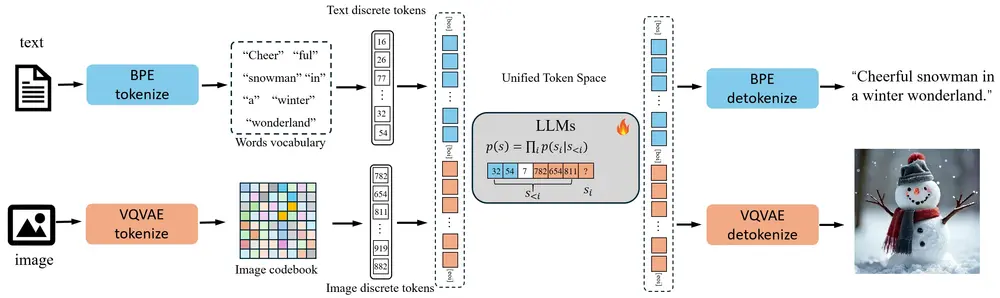
工作原理
图像编码:使用 VQGAN(Vector Quantized Generative Adversarial Network)将图像编码为离散的令牌,类似于 BPE(Byte Pair Encoding)对文本的处理。 统一嵌入空间:将图像令牌和文本令牌统一到一个共享的嵌入空间中,使模型能够同时处理视觉和语言任务。 继续训练:基于现有的 LLMs,通过少量的高质量图像-文本对数据进行继续训练,提升模型的多模态能力。 多模态任务优化:通过统一的令牌空间,使视觉生成和理解任务能够相互增强,而不是相互干扰。
实验与性能
视觉生成性能
Liquid 在多个基准测试中表现出色。例如,在 GenAI-Bench 上,无论是基础提示还是高级提示,Liquid 均取得了更高的总体评分,表明其生成的图像与输入文本提示在语义上更加一致。在 MJHQ-30K 上,Liquid 的 FID 值为 5.47,不仅比所有其他自回归方法更低,还超越了SD v2.1 和 SDXL,表明其能够生成高质量的图像。

视觉理解与生成的相互提升
为了验证视觉生成和理解任务是否能够相互增强,研究人员进行了三组实验。实验结果显示,增加视觉理解数据能够增强视觉生成能力,反之亦然。这表明,当视觉生成和理解的标记统一时,它们可以共享共同的优化目标,从而相互增强。
视觉生成对语言能力的影响
研究人员还评估了 Liquid 在多模态混合训练后对语言能力的影响。结果显示,虽然在模型规模较小时,多模态混合训练会对语言性能产生一定影响,但随着模型规模的增加,这种影响逐渐消失。这表明,更大的模型具有足够的容量来同时处理视觉和语言任务,而不会相互干扰。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











