
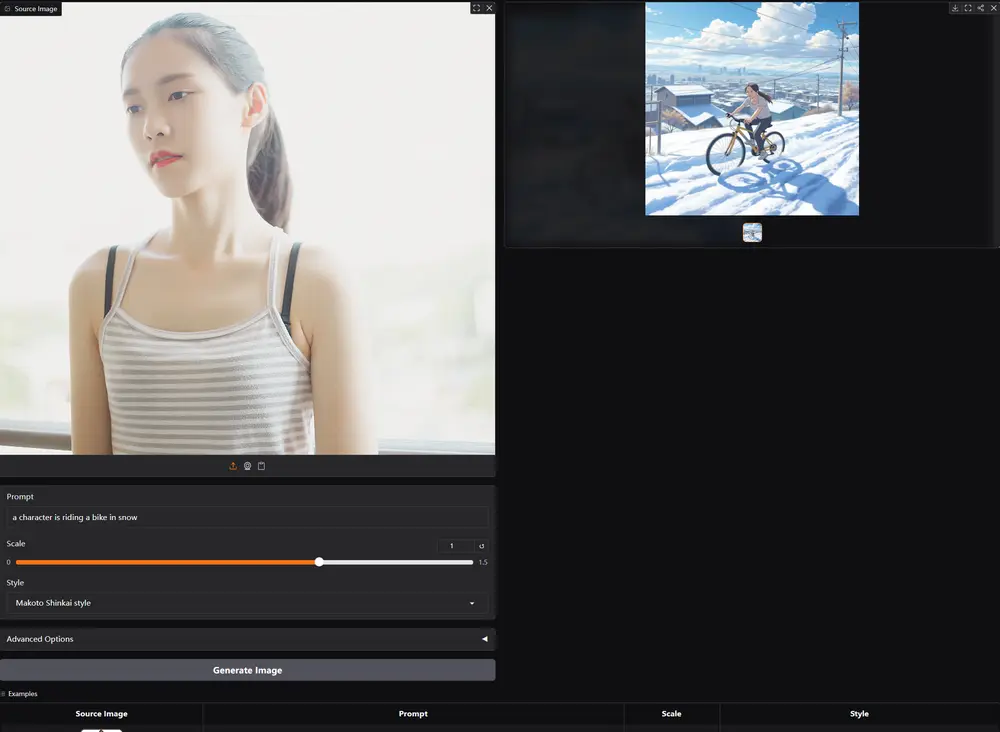
腾讯混元团队与InstantX团队近日联合推出了一种全新的角色定制方法——InstantCharacter。这一方法无需调优,仅通过单张图像即可实现高保真、文本可控且角色一致的图像生成,支持多种下游任务。InstantCharacter基于Flux模型,在角色驱动图像生成领域树立了新的标杆。
- 项目主页:https://instantcharacter.github.io
- GitHub:https://github.com/Tencent/InstantCharacter
- 模型:https://huggingface.co/tencent/InstantCharacter
- Demo:https://huggingface.co/spaces/InstantX/InstantCharacter
- ComfyUI插件:https://github.com/jax-explorer/ComfyUI-InstantCharacter (此插件需要45G显存才能运行)
背景与挑战
当前基于学习的角色定制方法主要依赖于U-Net架构,存在以下两大问题:
泛化能力有限:难以应对多样化角色外观、姿势和风格的需求。 图像质量受损:生成结果往往无法保持高保真度。
同时,基于优化的方法需要针对特定主体进行微调,这虽然能提升生成精度,但不可避免地降低了文本可控性。为解决这些问题,研究团队提出了InstantCharacter——一个基于扩散变换器(DiT)的可扩展角色定制框架。

InstantCharacter的核心优势
InstantCharacter展示了三大核心优势,使其在角色驱动图像生成领域脱颖而出:
1. 开放域个性化与高保真生成
InstantCharacter能够在多样化的角色外观、姿势和风格下实现开放域个性化生成,同时保持高保真结果。无论是卡通角色还是写实人物,它都能精准捕捉并保留角色特征。
2. 可扩展适配器模块
该框架引入了一个带有级联变换器编码器的可扩展适配器模块,能够有效解析开放域角色特征,并与现代扩散变换器的潜在空间无缝交互。这种设计显著提升了框架对复杂角色特征的处理能力。
3. 系统化的数据集与双重学习路径
为了高效训练框架,团队构建了一个包含千万级样本的大型角色数据集。该数据集被系统地组织为两类子集:
配对子集:多视角角色图像,用于优化身份一致性。 非配对子集:文本-图像组合,用于增强文本可编辑性。
这种双重数据结构通过不同的学习路径,支持身份一致性和文本可编辑性的同步优化。
方法与技术细节
1. 现代扩散变换器的优势
与传统的U-Net架构相比,现代扩散变换器(DiTs)在生成和编辑任务中展现了前所未有的保真度和能力,提供了更稳健的基础。然而,现有方法在开放域角色上的泛化能力仍然不足,尤其是在大规模扩散变换器(如12B参数)上尚未有成功验证的研究。
2. InstantCharacter的创新点
InstantCharacter围绕两大创新展开:
可扩展适配器模块:由多个堆叠的变换器编码器组成,逐步优化角色表示,支持与DiT潜在空间的有效交互。 渐进式三阶段训练策略: 第一阶段:从非配对的低分辨率数据开始预训练,初步学习角色特征。 第二阶段:逐步过渡到更高分辨率的数据,优化角色一致性。 第三阶段:利用配对的高分辨率数据进行微调,进一步提升生成质量。
通过灵活的适配器设计与分阶段学习策略的协同作用,InstantCharacter增强了通用角色定制能力,同时最大化保留了基础DiT模型的生成先验。
实验结果与性能
定性实验表明,InstantCharacter在生成高保真、文本可控且角色一致的图像方面表现出色。以下是其主要特点:
高保真度:生成的图像质量接近真实照片或高质量插画。 文本可控性:用户可以通过输入文本描述精确控制角色的动作、背景和风格。 角色一致性:即使在复杂的场景和多样的姿态下,角色的外观和特征始终保持一致。
这些优势使得InstantCharacter在影视制作、游戏开发、虚拟现实和科研模拟等多个领域具有广泛的应用潜力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











