Ovis-Image 是由阿里巴巴国际数字商务团队开发的 70亿参数 文本到图像(Text-to-Image)生成模型,专注于解决文生图系统中长期存在的文本模糊、拼写错误、排版失真等痛点。该模型在保持轻量级架构的同时,实现了接近百亿级模型的文本渲染质量,适用于海报、UI 原型、信息图等对文字清晰度要求严苛的场景。
- GitHub:https://github.com/AIDC-AI/Ovis-Image
- 模型:https://huggingface.co/AIDC-AI/Ovis-Image-7B
- Demo:https://huggingface.co/spaces/AIDC-AI/Ovis-Image-7B
模型基于 Ovis-U1 统一架构,融合 Ovis 2.5 多模态骨干网络 与 扩散式视觉解码器,并通过多阶段后训练优化,显著提升文本生成的准确性与视觉一致性。

核心定位:轻量高效的文本渲染图文生成模型
Ovis-Image的核心目标是解决传统图文生成模型“文本渲染模糊、参数庞大难部署、文字与视觉脱节”三大痛点,具体定位可概括为:
- 文本渲染专精:聚焦文字密集、排版敏感场景,优先保障文本清晰可读、拼写正确、语义对齐,而非单纯追求图像画质;
- 轻量高效部署:7B参数规模,单张中高端GPU即可运行,支持低延迟交互与批量生产,适配资源受限的商业化场景;
- 多场景兼容:兼顾通用图像生成能力,在文本渲染优势基础上,满足海报、UI、信息图等多样化设计需求;
- 多语言适配:支持中英文双语文本渲染,适配跨境电商、国际化设计等多语言场景。
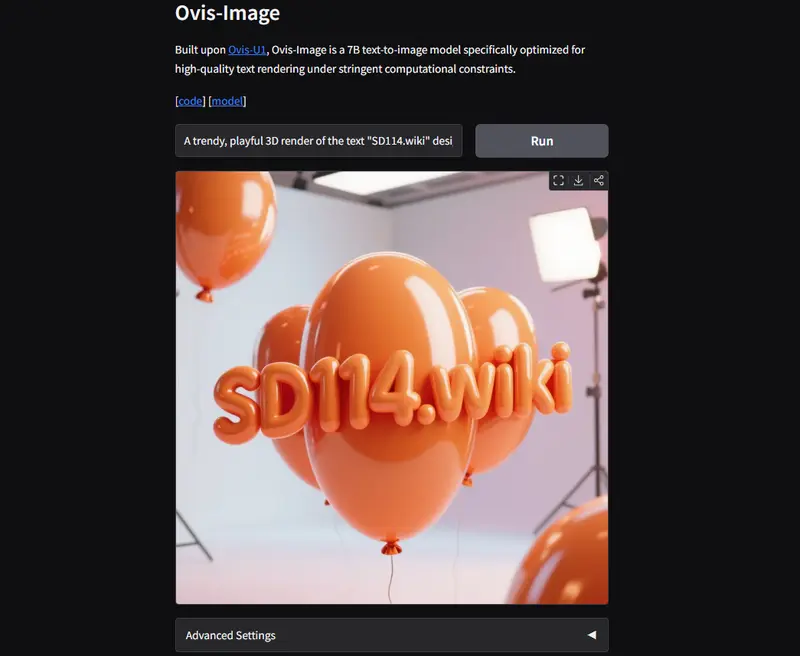
核心技术亮点:小参数实现大能力的底层逻辑
Ovis-Image之所以能在7B规模下实现超预期表现,源于架构设计、训练策略与技术融合的三重创新:
1. 架构设计:多模态骨干+扩散解码器的高效组合
- Ovis 2.5多模态骨干网络:专门针对多模态数据集训练,强化文本与视觉特征的对齐能力,解决“文本描述与生成图像中文字不一致”的核心问题,为精准文本渲染奠定基础;
- 扩散模型视觉解码器:结合RoPE(旋转位置编码)与流匹配(Flow Matching)训练目标,优化图像生成的细节还原度,尤其提升文本的边缘清晰度与字体辨识度;
- 冻结FLUX.1-schnell VAE解码器:复用成熟高效的VAE模块,在不增加训练复杂度的前提下,保障图像生成的整体质量与色彩还原度。
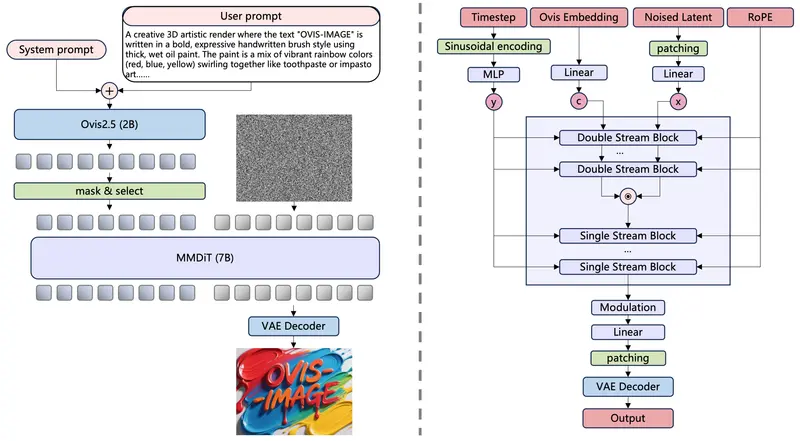
2. 训练策略:四阶段优化,聚焦文本渲染核心
Ovis-Image通过“预训练+微调+偏好优化+专项优化”的四阶段训练流程,实现文本渲染能力的精准提升:
- 预训练阶段:在大规模图像-文本对数据(含日常照片、插图、设计资产、UI原型)中学习通用视觉与文本对齐能力;
- 监督微调阶段:使用高质量图文数据优化,强调文本清晰度、排版合理性与视觉协调性;
- 偏好优化(DPO)阶段:基于用户偏好数据调整模型输出,提升文本渲染的实用性与美观度;
- 组相对策略优化(GRPO)阶段:专项针对文本渲染场景优化,重点提升字体适配、字号控制、排版布局的精准度。
3. 效率优化:兼顾性能与资源消耗
- 混合精度训练(bfloat16):在保证训练效果的前提下,降低显存占用,提升训练效率;
- Flash Attention优化:加速注意力计算过程,减少推理延迟,让7B模型在普通GPU上也能实现快速响应;
- 精简架构设计:去除冗余模块,聚焦文本渲染核心能力,在参数规模仅为同类模型1/3的情况下,实现相当甚至更优的文本渲染效果。
测试表现:文本渲染夺冠,通用能力不弱
Ovis-Image在多项权威数据集测试中表现突出,尤其在文本渲染相关指标上稳居前列:
1. 核心指标表现(文本渲染为主)
| 测试维度 | 具体表现 | 行业对比优势 |
|---|---|---|
| CVTG-2K数据集 | 单词准确率、NED(归一化编辑距离)、CLIPScore三项指标均获最高分 | 显著优于Qwen-Image等20B级模型 |
| LongText-Bench数据集 | 中英文长文本渲染质量接近闭源模型,文本可读性、排版合理性表现优异 | 解决传统模型长文本模糊、换行混乱问题 |
| 多语言文本渲染 | 中英文双语文本拼写正确率超95%,字体风格与图像场景适配度高 | 优于同类开源模型的单语言偏向性 |
2. 通用图像生成能力
- DPG-Bench数据集:在全局构图、实体还原、属性匹配等维度表现与大型模型相当,无明显短板;
- GenEval数据集:对象中心的图文生成任务中,可控性强,能精准还原文本描述的对象特征与场景关系;
- OneIG-Bench数据集:对齐度、推理能力表现优异,双语性能突出,适配多语言设计需求。
3. 计算效率对比
| 模型类型 | 参数规模 | A100 GPU推理延迟 | 显存占用 | 部署门槛 |
|---|---|---|---|---|
| Ovis-Image | 7B | 低(毫秒级) | 中等 | 单张中高端GPU即可部署 |
| Qwen-Image | 20B | 中高 | 高 | 需多张GPU或高端显卡 |
| Flux.1-dev | 百亿级 | 高 | 极高 | 仅适用于大规模算力集群 |
结论:Ovis-Image在计算效率上具有绝对优势,同时文本渲染质量不逊于大模型,实现“性能与效率的双赢”。
核心功能与应用场景
1. 三大核心功能
| 功能模块 | 核心能力 | 技术支撑 |
|---|---|---|
| 高质量文本渲染 | 生成清晰可读、拼写正确、排版合理的文本图像,支持多种字体、字号、布局调整 | 多模态对齐+GRPO专项优化 |
| 多语言文本生成 | 支持中英文双语文本渲染,保持文本与图像风格一致 | 多模态骨干网络的跨语言适配 |
| 高效通用生成 | 兼顾非文本场景的通用图像生成,满足多样化设计需求 | 扩散解码器+VAE优化 |
2. 典型应用场景
- 商业设计场景:海报、横幅、广告图生成(如跨境电商产品宣传图,可快速生成含中英文产品名称、卖点的高质量图像);
- UI/UX设计场景:UI原型、界面设计稿生成(支持按钮文本、标题文本、提示文本的清晰渲染,适配不同屏幕尺寸与布局);
- 信息可视化场景:信息图、数据报表可视化(将文字描述的数据分析结果生成含清晰文本标注的图表图像);
- 多语言内容创作:双语宣传材料、国际化产品手册设计(中英文文本同步渲染,保持字体风格与视觉一致性);
- 实时交互场景:设计工具插件、在线图像生成平台(低延迟推理,支持用户实时调整文本描述与排版,快速生成预览效果)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...